
学成在线
学成在线
视频:https://www.bilibili.com/video/BV1j8411N7Bm?p=1&vd_source=1a39594354c31d775ddc587407a55282
文档:https://cyborg2077.github.io/2023/02/10/XuechengOnlinePart3/#%E8%A7%86%E9%A2%91%E5%A4%84%E7%90%86
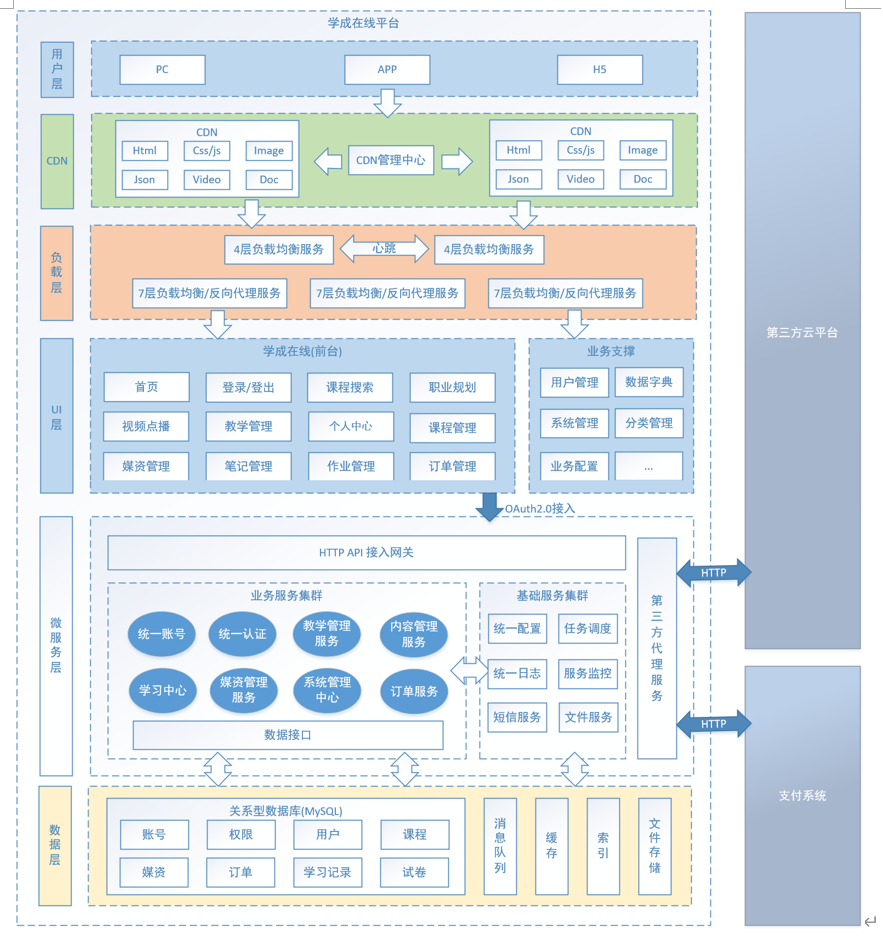
用户层:描述了本系统所支持的用户类型包括:pc用户、app用户、h5用户。pc用户通过浏览器访问系统、app用户通过android、ios手机访问系统,H5用户通过h5页面访问系统。
CDN:全称Content Delivery Network,即内容分发网络,本系统所有静态资源全部通过CDN加速来提高访问速度。系统静态资源包括:html页面、js文件、css文件、image图片、pdf和ppt及doc教学文档、video视频等。
- 系统的CDN层、UI层、服务层及数据层均设置了负载均衡服务,上图仅在UI层前边标注了负载均衡。 每一层的负载均衡会根据系统的需求来确定负载均衡器的类型,系统支持4层负载均衡+7层负载均衡结合的方式,4层负载均衡是指在网络传输层进行流程转发,根据IP和端口进行转发,7层负载均衡完成HTTP协议负载均衡及反向代理的功能,根据url进行请求转发
- UI层:描述了系统向pc用户、app用户、h5用户提供的产品界面。根据系统功能模块特点确定了UI层包括如下产品界面类型: 1)面向pc用户的门户系统、学习中心系统、教学管理系统、系统管理中心。 2)面向h5用户的门户系统、学习中心系统。 3)面向app用户的门户系统、学习中心系统。
- 微服务层将系统服务分类三类:业务服务、基础服务、第三方代理服务。 业务服务:主要为学成在线核心业务提供服务,并与数据层进行交互获得数据。 基础服务:主要管理学成在线系统运行所需的配置、日志、任务调度、短信等系统级别的服务。 第三方代理服务:系统接入第三方服务完成业务的对接,例如认证、支付、视频点播/直播、用户认证和授权。
- 数据层描述了系统的数据存储的内容类型,关系性数据库:持久化的业务数据使用MySQL。 消息队列:存储系统服务间通信的消息,本身提供消息存取服务,与微服务层的系统服务连接。 索引库:存储课程信息的索引信息,本身提供索引维护及搜索的服务,与微服务层的系统服务连接。 缓存:作为系统的缓存服务,作为微服务的缓存数据便于查询。 文件存储:提供系统静态资源文件的分布式存储服务,文件存储服务器作为CDN服务器的数据来源,CDN上的静态资源将最终在文件存储服务器上保存多份。
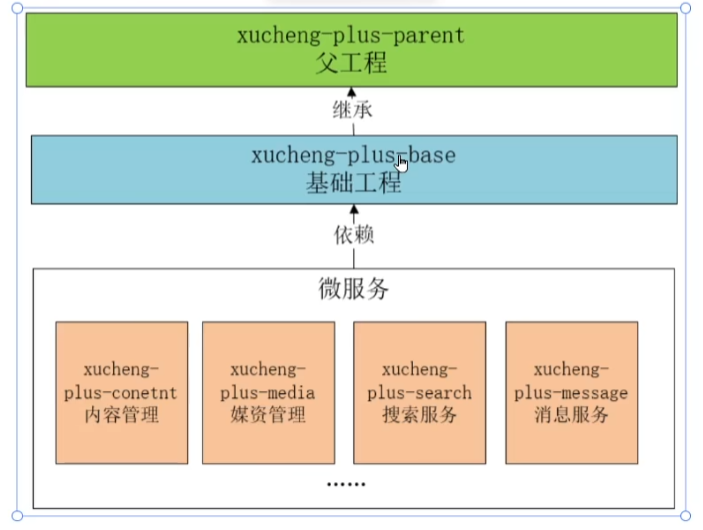
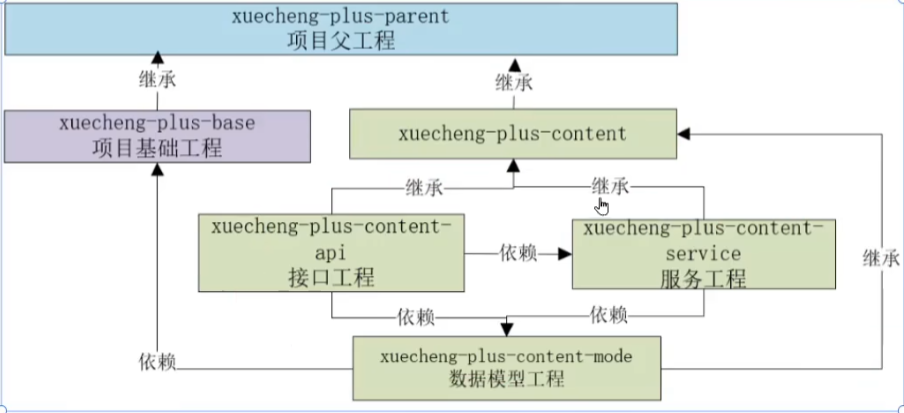
工程结构
数据模型

什么时候用vo什么时候用dto
多个前端调用接口的时候
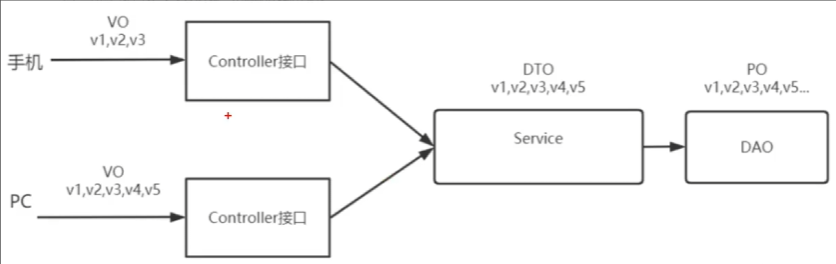
前端调接口 :VO/DTO
接口调业务:DTO
业务调数据:PO
swagger
xuecheng-plus-content-api导入依赖
bootstrap.yml
1
2
3
4
5
6swagger:
title: "学成在线内容管理系统"
description: "内容系统管理系统对课程相关信息进行管理"
base-package: com.xuecheng.content
enabled: true
version: 1.0.0启动类开启注解
1
升级为knife4j
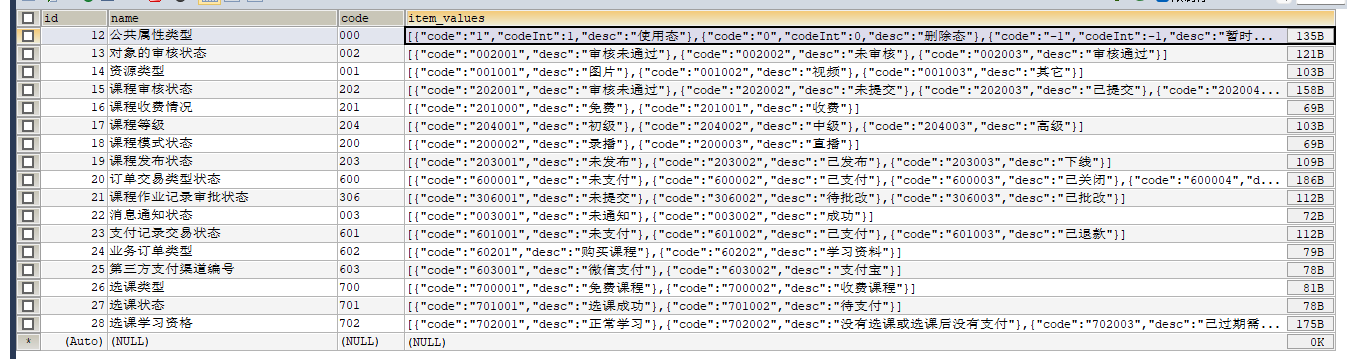
数据字典表:用于对应前端的响应
httpclient
.http文件,类似于postman,swagger,但是可以保存测试数据且是idea自带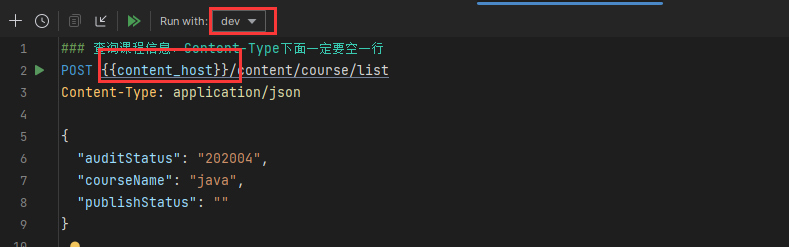
前端工程运行:看readme文件
JRS303校验
1
2
3
4<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-validation</artifactId>
</dependency>- 然后在po、dto等类的字段上加注解如
@NotEmpty - 最后在controller调用的时候给形参加注解
@validated
- 然后在po、dto等类的字段上加注解如

- JRS303分组校验
- 多个接口用一个模型类
0 总结
1 异常处理
@ControllerAdvice与@ExceptionHandler用来捕获异常@ResponseStatus用来确定响应数据
2 传入数据判断是否为空方法
在controller方法内部手动判断:
StringUtils.isNotEmpty实体类的数据上标注
@NotNull,然后在controller中的形参前面加上@Valid注解,再在全局异常中添加BindException异常类的捕获<img src=(https://myl-mdimg.oss-cn-beijing.aliyuncs.com/TyporaImg/学成在线.assets/image-20240303153429684.png“ alt=”image-20240303153429684” style=”zoom:50%;” />
3 controller与前端的数据传递
- 形参不带注解:此时参数名称一定要和请求参数的名称一致
- get方式提交,直接写参数
- 通过
HttpServletRequest接收:request.getParameter("username") - 通过java类对象接收
- 形参带注解
@RequestParam:有value、require、defaultValue字段可填充@PathVariable:支持类似于:user/get/mac/{macAddress}的请求@ModelAttribute("user"):会将客户端传递过来的参数按名称注入到指定对象中,并且会将这个对象自动加入ModelMap中,便于View层使用
4 树形查询
left join连接表(可以是相同的表)指定
resultMap为一个值,然后再在指定的resultMap中设置映射关系并将结果返回。

5 视频分块上传
RandomAccessFile实现文件的分块和合并- 判断是否一致 ==>
DigestUtils.md5Hex()
6 @Transactional
自调用的时候需要声明一个代理对象来方便进行事务的管理
<img src=(https://myl-mdimg.oss-cn-beijing.aliyuncs.com/TyporaImg/学成在线.assets/image-20240304110055984.png“ alt=”image-20240304110055984” style=”zoom:67%;” />
@Transactional即声明式事务管理, 建立在AOP之上的。其本质是对方法前后进行拦截,然后在目标方法开始之前创建或者加入一个事务,在执行完目标方法之后根据执行情况提交或者回滚事务。
7 freemarker
controller中返回
ModelAndView对象,在setViewName中设置重定向的页面文件,在addObject中传值<img src=(https://myl-mdimg.oss-cn-beijing.aliyuncs.com/TyporaImg/学成在线.assets/image-20240304142757986.png“ alt=”image-20240304142757986” style=”zoom:80%;” />
8 xxj-job
- 获取执行器序号、 执行器总数,然后用表的
id % 总数 == 序号来保证一个任务只会被一个执行器执行,用字段标识来保证一个任务只会被执行一次(乐观锁) - 用于视频转码作业
- 课程发布操作后,先更新数据库中的课程发布状态,更新后向Redis、ElasticSearch、MinIO写课程信息,只要在一定时间内最终成功写入数据即可
- 这里使用了feign远程调用,在向MinIO写信息的时候调用了Media服务的相关接口
- 熔断降级:返回null对象,然后再去判断是否为null来判断是否发生了故障
- 注意启动类开启注解
@EnableFeignClients
- 这里使用了feign远程调用,在向MinIO写信息的时候调用了Media服务的相关接口
9 ES
倒排索引过程
<img src=(https://myl-mdimg.oss-cn-beijing.aliyuncs.com/TyporaImg/学成在线.assets/image-20240304153213090.png“ alt=”image-20240304153213090” style=”zoom:67%;” />
概念
- 文档:一条完整的数据,包括索引、名称等,以json方式存储
- 字段:文档中的具体字段,类似于表格的列
- 索引:就是相同类型的文档的集合,类似于表。eg:用户的索引、商品的索引、订单的索引…
- 映射(mapping):索引中字段的约束信息,类似于表的结构约束。
安装ik分词器
索引库的操作
<img src=(https://myl-mdimg.oss-cn-beijing.aliyuncs.com/TyporaImg/学成在线.assets/image-20240304154138185.png“ alt=”image-20240304154138185” style=”zoom:67%;” />
文档的操作
<img src=(https://myl-mdimg.oss-cn-beijing.aliyuncs.com/TyporaImg/学成在线.assets/image-20240304154206085.png“ alt=”image-20240304154206085” style=”zoom:67%;” />
搜索结果处理
- 排序
- 分页
- 高亮
- 给文档中的所有关键字都添加一个标签,例如
<em>标签 - 页面给
<em>标签编写CSS样式
- 给文档中的所有关键字都添加一个标签,例如
demo
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
void testMatchAll() throws IOException {
// 1. 准备Request对象,对应 GET /hotel/_search
SearchRequest request = new SearchRequest("hotel");
// 2. 组织DSL参数 对应 "query": {"match_all": {}}
request.source().query(QueryBuilders.matchAllQuery());
// 3. 发送请求,得到相应结果
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
System.out.println(response);
}
/*
创建SearchRequest对象,指定索引库名
利用request.source()构建DSL,DSL中可以包含查询、分页、排序、高亮等
利用client.search()发送请求,得到响应
关键API:
一个是request.source(),其中包含了query、order、from、size、highlight等所有功能
另一个是QueryBuilders,其中包含了match、term、function_score、bool等各种查询
*/数据聚合:用来实现对数据的统计分析计算等
10 Spring Security
继承
UserDetailsService接口,重写loadUserByUsername()方法返回
UserDetails对象
DaoAuthenticationProviderCustom extends DaoAuthenticationProvider- 刚刚我们重写的
loadUserByUsername()方法是由DaoAuthenticationProvider调用的 - 重写
additionalAuthenticationChecks()里面会比对密码,但不是所有的登录方式都有密码 - 然后在
WebSecurityConfig extends WebSecurityConfigurerAdapter中配置刚刚定义的DaoAuthenticationProvider
- 刚刚我们重写的
OAuth2.0
- 客户端请求资源拥有者授权
- 资源拥有者授权客户端,即用户授权目标网站访问自己的用户信息
- 目标网站携带授权码请求认证
- 认证通过,颁发令牌
- 目标网站携带令牌请求资源服务器,获取资源
- 资源服务器校验令牌通过后,提供受保护的资源
JWT:
- 好处:在认证服务颁发令牌给客户端后,客户端携带令牌请求其他服务的资源时,其他服务可以直接校验令牌合法性,无需再经过认证服务。
- 缺点:JWT令牌占用空间较大
- 无状态认证:用户身份信息存储在令牌中,服务端从JWT解析出用户信息
- 有状态认证:用户信息通过session存储在服务端
- 组成
- 头部Header:令牌类型及使用的哈希算法
- 负载Payload:用户信息
- 签名Sugbature:根据密钥进行加密前两部分,防止篡改
SecurityContextHolder获取当前访问的用户信息:Authentication对象- 原理:
ThreadLocal
- 原理:
用户授权
- 授权认证服务器
@EnableAuthorizationServer==> 配置资源列表:xuecheng-plus - 资源服务器
@EnableResourceServer==> 定义资源id:xuecheng-plus - 接口添加
@PreAuthorize("hasAuthority('权限标识符')")即可 - 授权定义在
loadUserByUsername方法中返回的UserDetails中,是一个String类型的数组 - 没有权限抛出
AccessDeniedException在全局异常处理器中捕获即可
- 授权认证服务器
11 验证码
Kaptcha
12 RabbitMQ
异步通讯
<img src=(https://myl-mdimg.oss-cn-beijing.aliyuncs.com/TyporaImg/学成在线.assets/image-20240306162652779.png“ alt=”image-20240306162652779” style=”zoom:67%;” />
0 坑
1 StringUtils
- StringUtils.isNotEmpty

- 会去掉
null和""两种情况,所以比... != null好
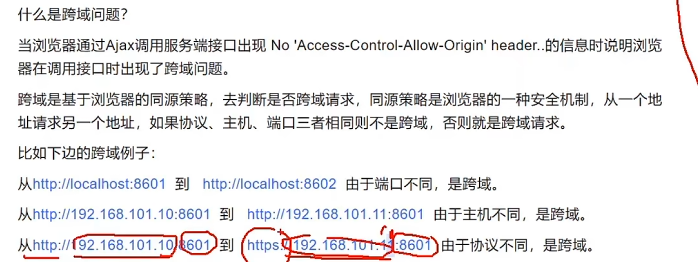
2 跨域请求问题
从一个地址请求到另一个地址:协议、端口、主机三者有一个不一致就属于跨域
- 端口的跨域
- 主机的跨域
- 协议的跨域:
http和https
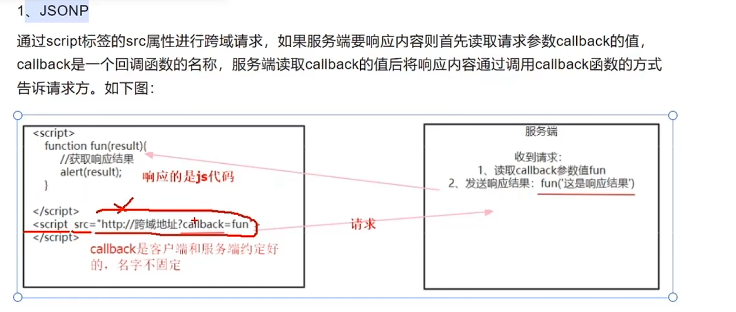
解决一:利用script跨域跨域的特性解决
解决二:服务端添加响应头
服务端收到请求判断这个origin是否允许跨域,如果允许则在响应头中说明允许该来源的跨域请求:
1
Access-Control-Allow-Origin:http//localhost:8601
允许任何域名来源跨域
1
Access-Control-Allow-Origin:*
定义一个
GlobalCorsConfig类
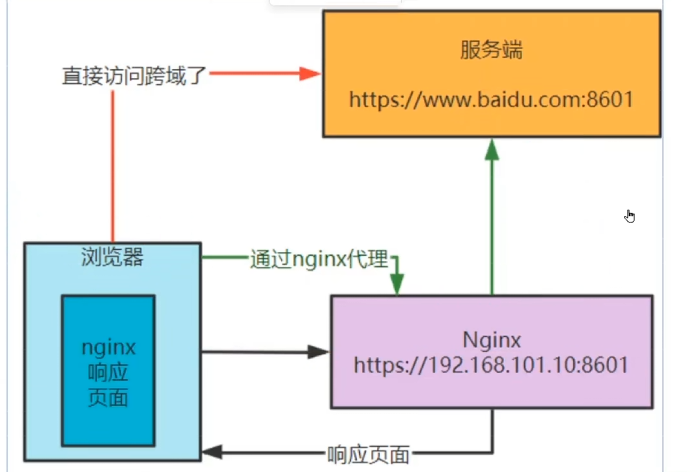
解决三:通过nginx代理跨域
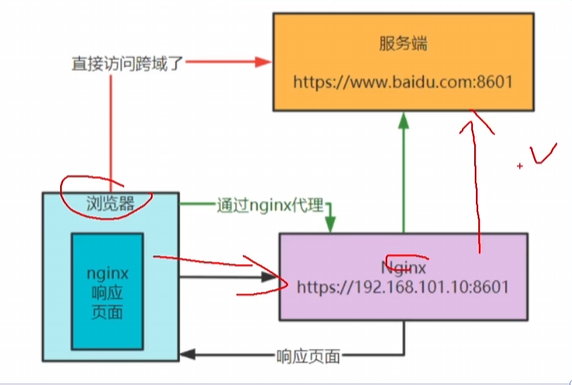
3 开热点会占用端口!
4 maven 3.6.1
- maven版本对项目也是有影响的
5 nginx
设置最大上传文件大小,默认是1M
<img src=(https://myl-mdimg.oss-cn-beijing.aliyuncs.com/TyporaImg/学成在线.assets/image-20240304144704820.png“ alt=”image-20240304144704820” style=”zoom:67%;” />
1 nacos
- Spring Cloud:一套规范
- Spring Cloud alibaba:nacos服务注册中心、配置中心
概念
- namespace:用于区分环境,比如开发环境、测试环境、生产环境
- group:用于区分项目
实现nacos上报服务步骤
启动虚拟机,然后启动docker容器
1
systemctl start docker
在父工程上添加
spring-cloud-alibaba-dependencies依赖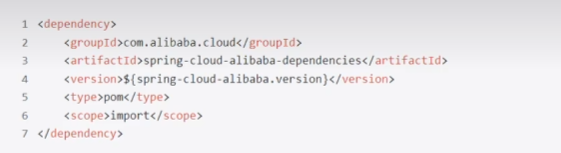
在子模块上添加依赖用于上报信息(谁需要启动就上报谁)
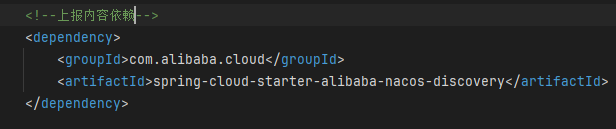
在子模块的配置文件中配置nacos信息
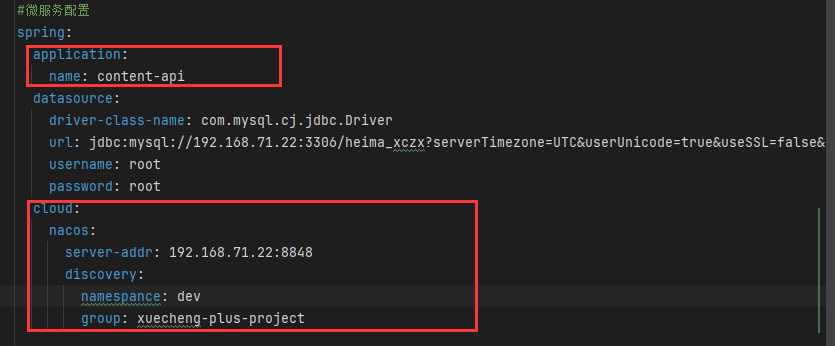
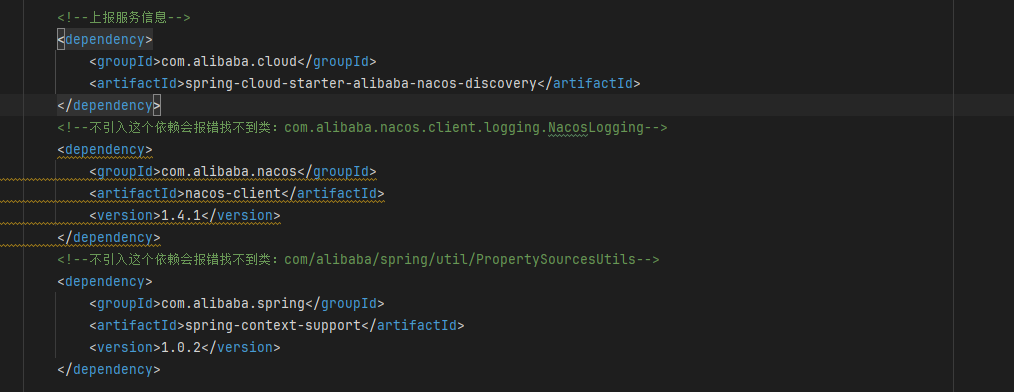
坑
实现nacos配置中心
好处:不用重启就可以修改配置、多服务的时候配置集中
配置分类
- 项目特有的配置
- 公共的配置
nacos如何定位一个具体的配置文件
通过namespace、group找到具体的环境和具体的项目
通过dataid找到具体的配置文件,dataid组成
(content-setrvice)-(dev).(yaml):服务名-环境名.yaml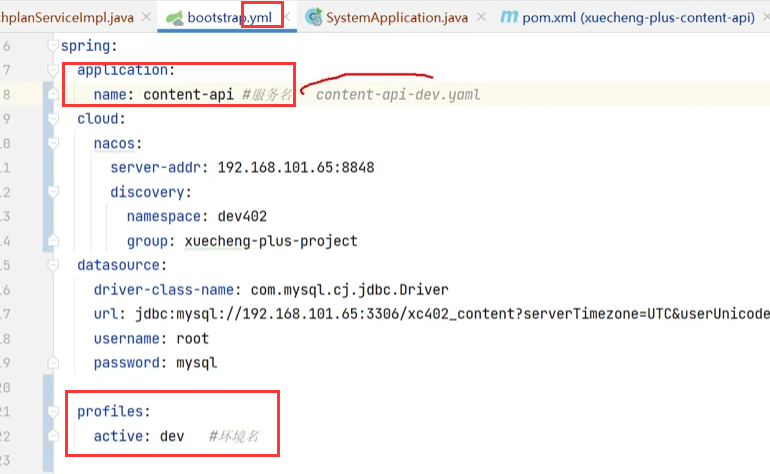
在nacos中创建好配置
根据上述起:dataid,以及group

随后写入配置并发布
服务中引入依赖
1
2
3
4<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-nacos-config</artifactId>
</dependency>坑
1
2
3
4
5
6
7
8
9
10
11
12<!--不引入这个依赖会报错找不到类:com.alibaba.nacos.client.logging.NacosLogging-->
<dependency>
<groupId>com.alibaba.nacos</groupId>
<artifactId>nacos-client</artifactId>
<version>1.4.1</version>
</dependency>
<!--不引入这个依赖会报错找不到类:com/alibaba/spring/util/PropertySourcesUtils-->
<dependency>
<groupId>com.alibaba.spring</groupId>
<artifactId>spring-context-support</artifactId>
<version>1.0.2</version>
</dependency>
配置扩展:读取别的配置信息
- 在content-api中配置引入content-service的配置
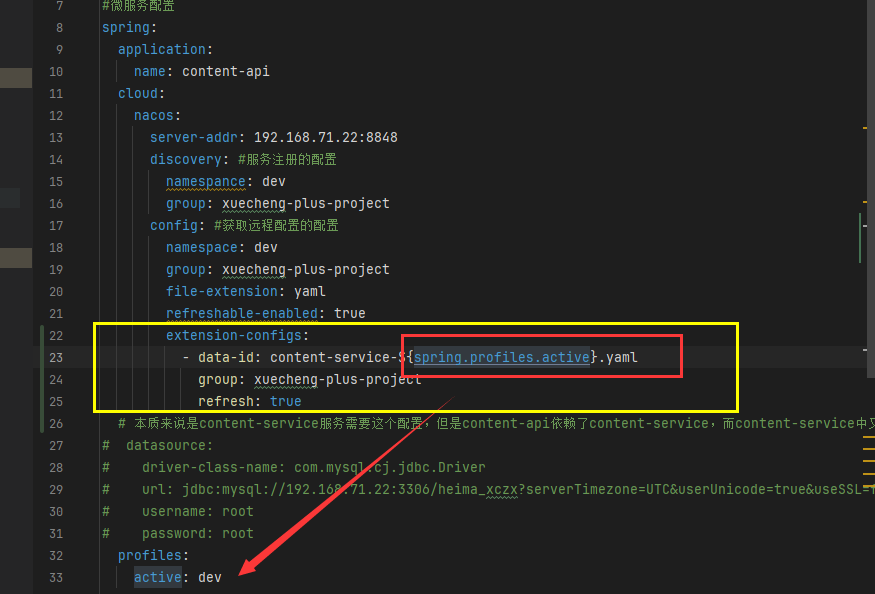
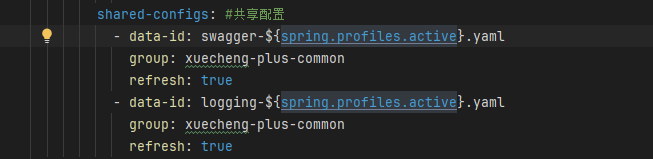
公共配置:读取公共配置信息
- 在nacos中分别创建
swagger-dev.yaml与loggin-dev.yaml均属于xuecheng-plus-common组
- 在nacos中分别创建
优先级
- 项目应用名配置文件>扩展配置文件>共享配置文件>本地配置文件
如何让本地优先?(场景:本地想多端口启动同一个服务)
修改远程配置文件
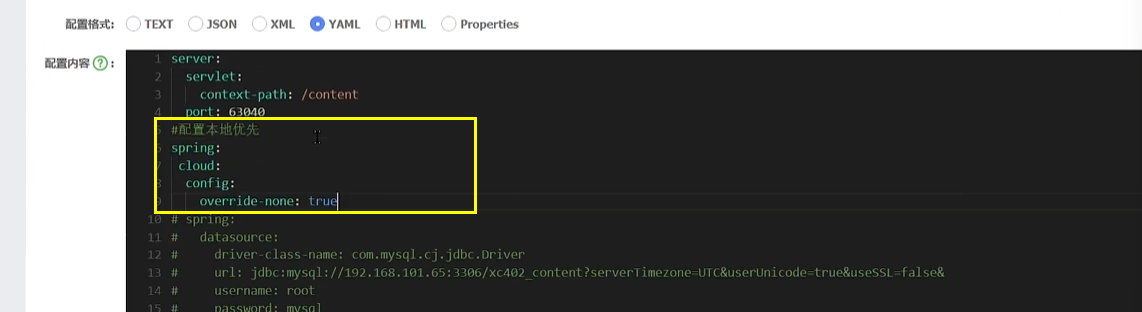
然后启动的时候添加VM参数:
2 分布式文件系统
将若干计算机通过网络连接共同提供文件存储服务
NFS
- GFS
- HDFS
云计算厂家
- 阿里云对象存储服务(OSS)
MinIO
3 媒资管理服务
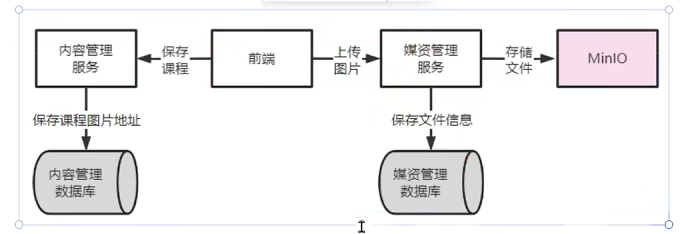
3.1 上传图片(MinIO)
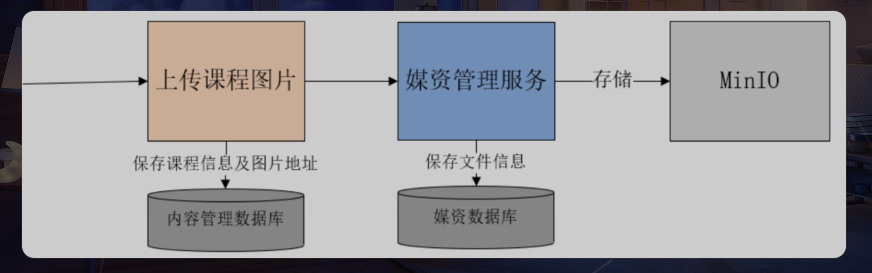
- 前端进入上传图片界面
- 上传图片,请求媒资管理服务
- 媒资管理服务将图片文件存储在MinIO
- 媒资管理记录文件信息到数据库
- 保存课程信息,在内容管理数据库保存图片地址
3.2 上传视频(断点续传)
断点续传:将上传和下载功能分为多个部分,防止中途断网导致的重新下载和上传文件
实现:文件分块
前端上传前先把文件分成块
一块一块的上传,上传中断后重新上传。已上传的分块则不用再上传
各分块上传完成后,在服务端合并文件
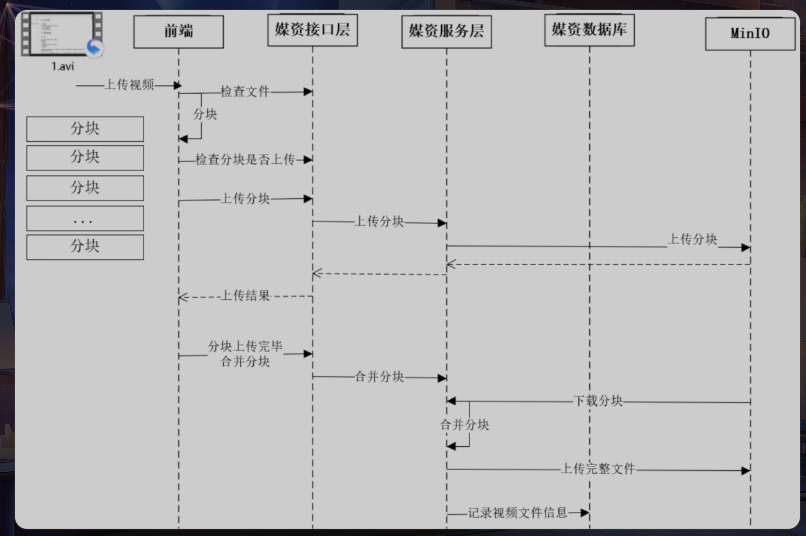
具体流程
- 前端上传文件前,请求媒资接口层检查文件是否存在
- 若存在,则不再上传
- 若不存在,则开始上传,首先对视频文件进行分块
- 前端分块进行上传,上传前首先检查分块是否已经存在
- 若分块已存在,则不再上传
- 若分块不存在,则开始上传分块
- 前端请求媒资管理接口层,请求上传分块
- 接口层请求服务层上传分块
- 服务端将分块信息上传到MinIO
- 前端将分块上传完毕,请求接口层合并分块
- 接口层请求服务层合并分块
- 服务层根据文件信息找到MinIO中的分块文件,下载到本地临时目录,将所有分块下载完毕后开始合并
- 合并完成后,将合并后的文件上传至MinIO
- 前端上传文件前,请求媒资接口层检查文件是否存在
相关问题

3.3 视频转码(XXL-JOB)
转换视频编码
ffmpeg:转码工具
目标:
.avi转.mp4
分布式任务处理
- 视频上传成功需要对视频格式进行处理,如何用Java程序对视频进行处理呢?
- 这里有一个关键的需求就是:当视频比较多的时候,我们如何高效的处理
- 如何去高效的处理一批任务呢?
- 多线程
- 多线程是充分利用单机的资源
- 分布式+多线程
- 充分利用多台计算机,每台计算机使用多线程处理
- 多线程
- 方案2的可扩展性更强,同时方案二也是一种分布式任务调度的处理方案
- JDK也为我们提供了相关支持,如Timer、ScheduledExecutor
- 缺点是不能胜任复杂的任务
1 | public static void main(String[] args) { |
1 | public static void main(String[] args) { |
Quartz: Quartz设计的核心类包括Job,Trigger以及Scheduler。- Job负责定义需要执行的任务
- Trigger负责设置调度策略
- Scheduler将二者组装在一起,并触发任务开始执行
XXL-Job
XXL-JOB:是一个轻量级分布式任务调度平台,其核心设计是开发迅速、学习简单、轻量级、易扩展,现已开放源代码并接入多家公司线上产品线,开箱即用组成:调度中心、执行器、任务
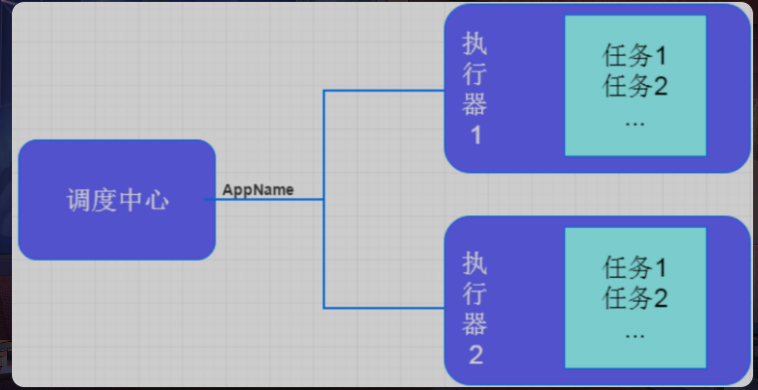
- 调度中心
- 负责管理调度信息,按照调度配置发出调度请求,自身不承担业务代码
- 主要职责为执行器管理、任务管理、监控运维、日志管理等
- 任务执行器
- 负责接收调度请求并执行任务逻辑
- 主要职责是注册服务、任务执行服务(接收到任务后会放入线程池中的任务队列)、执行结果上报、日志服务等
- 任务
- 负责执行具体的业务逻辑
- 调度中心
执行流程
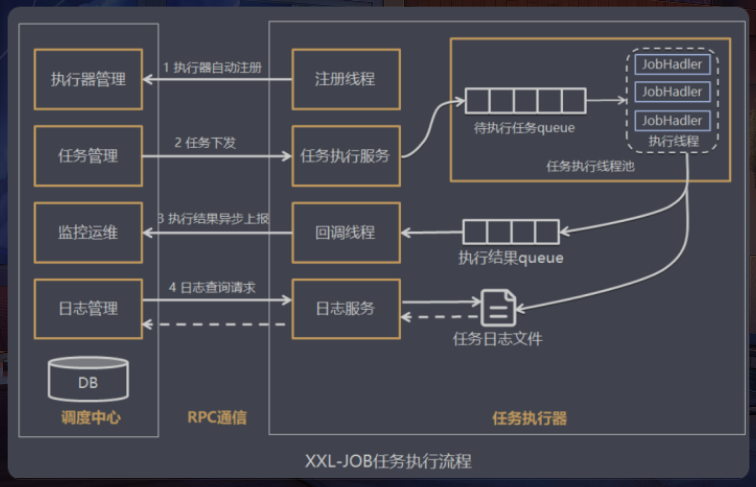
- 任务执行器根据配置的调度中心的地址,自动注册到调度中心
- 达到任务出发条件,调度中心下发任务
- 执行器基于线程池执行任务,并把执行结果放入内存队列、把执行日志写入日志文件中
- 执行器消费内存队列中的执行结果,主动上报给调度中心
- 当用户在调度中心查看任务日志,调度中心请求任务执行器,任务执行器读取任务日志文件并返回日志详情
XXL-job部署
首先下载XXL-JOB
使用IDEA打开项目
- xxl-job-admin:调度中心
- xxl-job-core:公共依赖
- xxj-job-executor-samples:执行器Sample示例
- xxl-job-executor-sample-springboot:SpringBoot版本,通过SpringBoot管理执行器
- xxl-job-executor-sample-frameless:无框架版本
根据数据库脚本创建数据库,修改数据库连接信息和端口,启动xxl-job-admin,访问http://localhost:8080/xxl-job-admin/toLogin
- 账号密码:admin/123456
启动成功之后,可以选择在Linux上运行
使用maven命令,将xxl-job-admin打包,然后将其上传至Linux中,使用命令启动
1
nohup java -jar /绝对路径/xxl-job-admin-2.3.1.jar &
执行器注册
在网页上新建一个执行器
在媒资服务中添加依赖
1
2
3
4<dependency>
<groupId>com.xuxueli</groupId>
<artifactId>xxl-job-core</artifactId>
</dependency>在nacos中配置
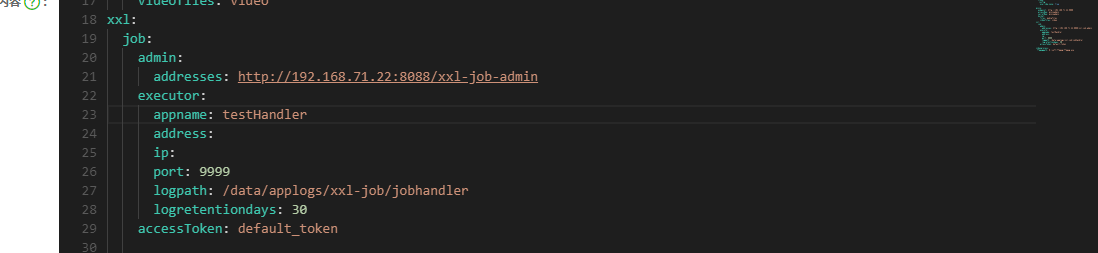
将示例工程下的配置类
XxlJobConfig拷贝到media-service工程下,该类中的属性就是获取配置文件中的配置得到的,同时提供了一个执行器的Bean
执行任务
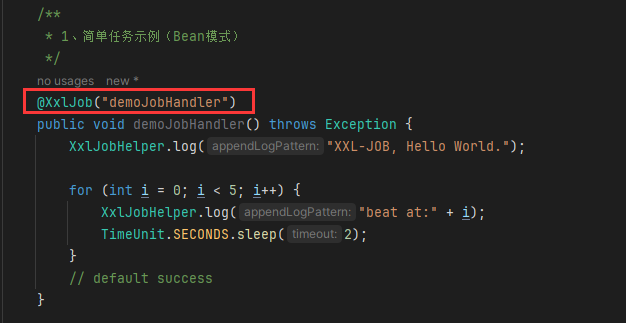
拷贝
SampleXxlJob到media-service项目的service/jobhandler包中在调度中心注册任务
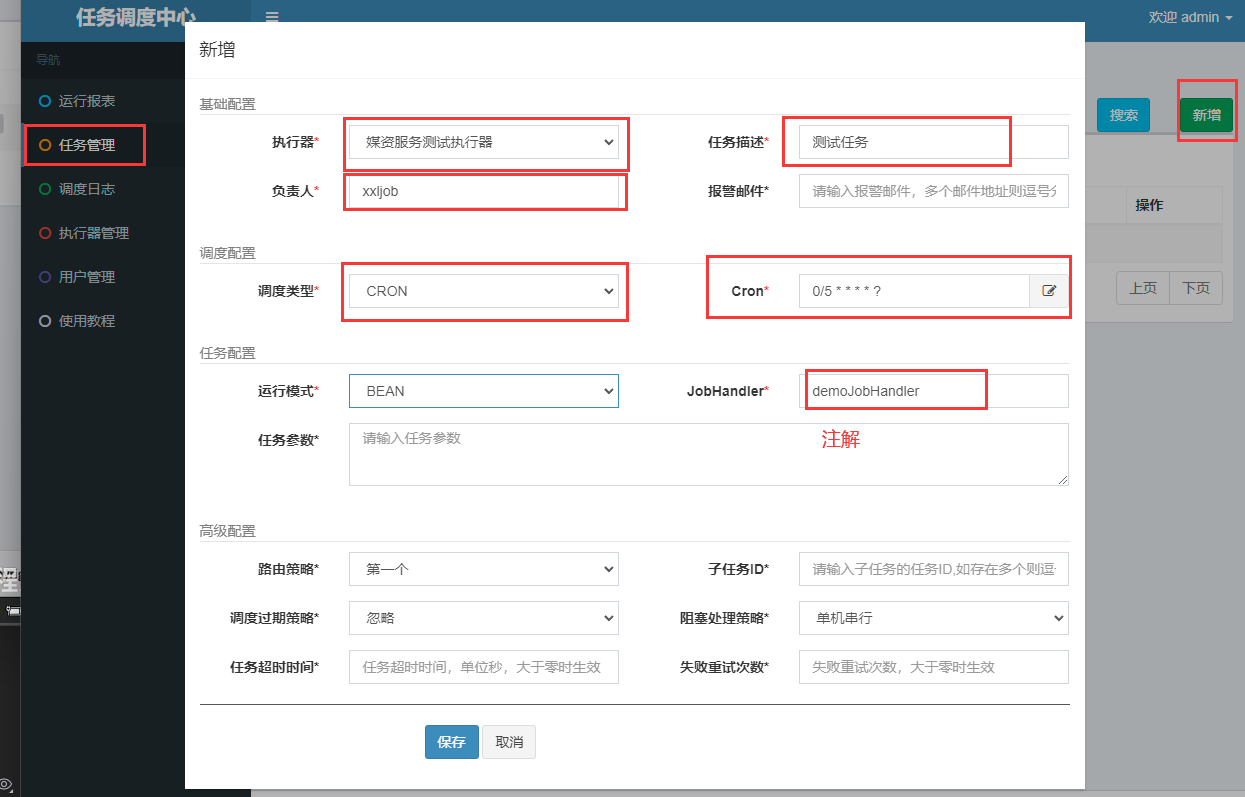
最后在调度中心开启任务
- 调度中心的高级配置说明
- 路由策略:有多个执行器的时候,选择让谁来执行,
- ```
- FIRST(第一个):固定选择第一个机器;
- LAST(最后一个):固定选择最后一个机器; - ROUND(轮询):; - RANDOM(随机):随机选择在线的机器; - CONSISTENT_HASH(一致性HASH):每个任务按照Hash算法固定选择某一台机器,且所有任务均匀散列在不同机器上。 - LEAST_FREQUENTLY_USED(最不经常使用):使用频率最低的机器优先被选举; - LEAST_RECENTLY_USED(最近最久未使用):最久未使用的机器优先被选举; - FAILOVER(故障转移):按照顺序依次进行心跳检测,第一个心跳检测成功的机器选定为目标执行器并发起调度; - BUSYOVER(忙碌转移):按照顺序依次进行空闲检测,第一个空闲检测成功的机器选定为目标执行器并发起调度; - SHARDING_BROADCAST(分片广播):广播触发对应集群中所有机器执行一次任务,同时系统自动传递分片参数;可根据分片参数开发分片任务;1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134- 子任务id:执行完这个任务后再执行的任务id
- 调度过期策略:
- 阻塞过期策略:
- 任务超时时间
- 失败重试次数
- 分片广播

- 场景:
- 分片任务场景:10个执行器的集群来处理10w条数据,每台机器只需要处理1w条数据,耗时降低10倍
- 广播任务场景:广播执行器同时运行shell脚本、广播集群节点进行缓存更新等
- 所以广播分片方式不仅可以充分发挥每个执行器的能力,并且根据分片参数可以控制任务是否执行,最终灵活控制了执行器集群的分布式处理任务
#### 作业分片方案
- 任务添加成功后,对于要处理的任务,会添加到待处理任务表中,现在启动多个执行器实例去查询这些待处理任务,此时如何保证多个执行器不会重复执行任务?
- 每个执行器收到广播任务有两个参数,**分片序号**和**分片总数**。每个执行器从数据表取任务时,可以用`任务id`对`分片总数`取`模`,如果等于该执行器的分片序号,则执行此任务

#### 保证任务不重复执行
- 通过作业分片方案,保证了执行器之间分配的任务不重复执行
- 但是如果同一个执行器,在处理一个视频的时候,还没有处理完,此时调度中心又来了一次请求调度,为了不重复处理同一个视频,该怎么办?
- 配置调度过期策略

- 选择忽略
- 配置阻塞处理策略:就是当前执行器正在执行任务还没有结束时,调度中心又请求调度,此时该如何处理

- 选择`丢弃后续调度`,避免重复调度
- 最后是保证任务的幂等性:对于数据的操作不论多少次,操作的结果始终是一致的。
- 执行器接收调度请求去执行任务,要有办法去判断该任务是否处理完成,如果处理完则不再处理,即使重复调度处理相同的任务也不能重复处理相同的视频。
- 幂等性的常用方案
- 数据库约束,例如:唯一索引、主键
- 乐观锁,长用户数据库,更新数据时根据乐观锁状态去更新
- 唯一序列号,操作传递一个唯一序列号,操作时判断与该序列号相等,则执行
- 这里我们在数据库视频处理表中**添加状态处理字段**,视频处理完成**更新状态为完成**,执行视频前判断状态是否完成,如果完成则不再处理
#### 业务流程
- 确定了分片方案,下面梳理视频上传以及处理的业务流程

- 上传视频成功,向视频待处理表中添加记录,视频处理的详细流程如下

- 任务调度中心广播作业分片
- 执行器收到广播作业分片,从数据库读取待处理任务

- 执行器根据任务内容MinIO下载要处理的文件
- 执行器启动多线程去处理任务
- 任务处理完成,上传处理后的视频到MinIO
- 将更新任务处理结果,如果视频处理完成,除了更新任务处理结果之外,还要将文件的访问地址更新至任务处理表及文件中,最后将任务完成记录写入历史表
#### 分布式锁
- 为了保证任务不重复执行,需要加锁
- 如果是多个执行器分布式部署,不能保证同一个视频只有一个执行器处理。现在要实现分布式环境下所有虚拟机中的线程去同步执行就需要让多个虚拟机去共用一个锁,虚拟机可以分布式部署,锁也可以分布式部署,如下图:

- 虚拟机都去抢占同一个锁,锁是一个单独的程序提供加锁、解锁服务
- 该锁不属于某个虚拟机,而是分布式部署,由多个虚拟机共享,这种锁叫**分布式锁**
- 实现
- 基于数据库:利用数据库主键唯一的特点(**本次实现**)
- 基于redis:redis提供了分布式锁的实现方案,比如SETNX
- SETNX是去set一个不存在的key。多个线程设置同一个key只会有一个线程设置成功,设置成功的拿到锁
- 基于zookeeper:多线程向zookeeper创建一个子目录,只会有一个创建成功,谁创建成功谁拿到锁
#### 面试tip
- 
- 
- 
### 3.4 绑定媒资
## 4 课程发布模块

### 4.1 课程预览
1. 教学机构用户在课程管理中可对该机构所管理的课程进行检索
2. 点击某课程数据后的预览链接,即可对该课程进行预览,可以看到发布后的详情页面
3. 点即课程目录中的具体章节,查看视频是否正常播放
#### java模板引擎
- 根据前面的数据模型分析,课程预览就是把课程的相关信息进行整合,在课程预览界面进行展示,课程预览界面与课程发布的课程详情界面一致,保证了教学机构人员发布前看到的是什么样,发布后也会看到什么样
- 所以模板引擎就是`模板 + 数据 = 输出`。JSP页面就是模板,页面中嵌入的JSP标签就是数据,两者相结合输出HTML网页
- 常用的Java模板引擎还有那些?
- JSP
- **Freemarker**:本项目采用
- Thymeleaf
- Velocity
#### Freemarker
- 引入依赖
```xml
<!-- Spring Boot 对结果视图 Freemarker 集成 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-freemarker</artifactId>
</dependency>
- FIRST(第一个):固定选择第一个机器;
- ```
- 路由策略:有多个执行器的时候,选择让谁来执行,
nacos中的配置
1
2
3
4
5
6
7
8
9
10
11spring:
freemarker:
enabled: true
cache: false #关闭模板缓存,方便测试
settings:
template_update_delay: 0
suffix: .ftl #页面模板后缀名
charset: UTF-8
template-loader-path: classpath:/templates/ #页面模板位置(默认为 classpath:/templates/)
resources:
add-mappings: false #关闭项目中的静态资源映射(static、resources文件夹下的资源)- 并在contente-api的resource目录下创建templates目录
在contente-api的配置文件中引入nacos中远程配置
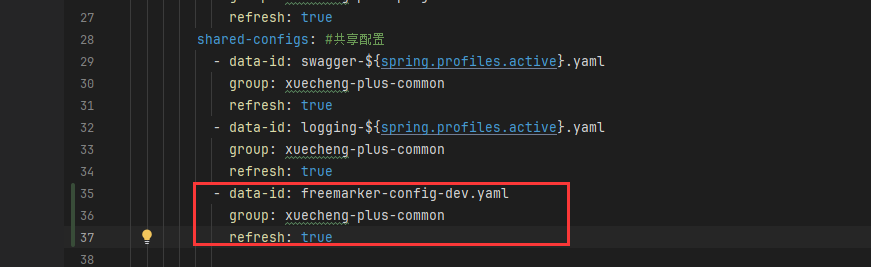
添加模板,在resource下创建templates目录(与配置文件中一致),添加test.ftl模板文件
1
2
3
4
5
6
7
8
9
10
<html>
<head>
<meta charset="utf-8">
<title>Hello World!</title>
</head>
<body>
Hello ${broski}!
</body>
</html>Controller中添加方法
1
2
3
4
5
6
7
8
public ModelAndView test() {
ModelAndView modelAndView = new ModelAndView();
modelAndView.setViewName("test");
modelAndView.addObject("broski", "Kyle");
return modelAndView;
}启动内容管理服务,访问http://localhost:53040/content/testfreemaker ,屏幕输出
Hello Kyle!
部署门户网站
文件服务及视频播放
加入nginx
<img src=(https://myl-mdimg.oss-cn-beijing.aliyuncs.com/TyporaImg/学成在线.assets/image-20240116203422988.png“ alt=”image-20240116203422988” style=”zoom:50%;” />
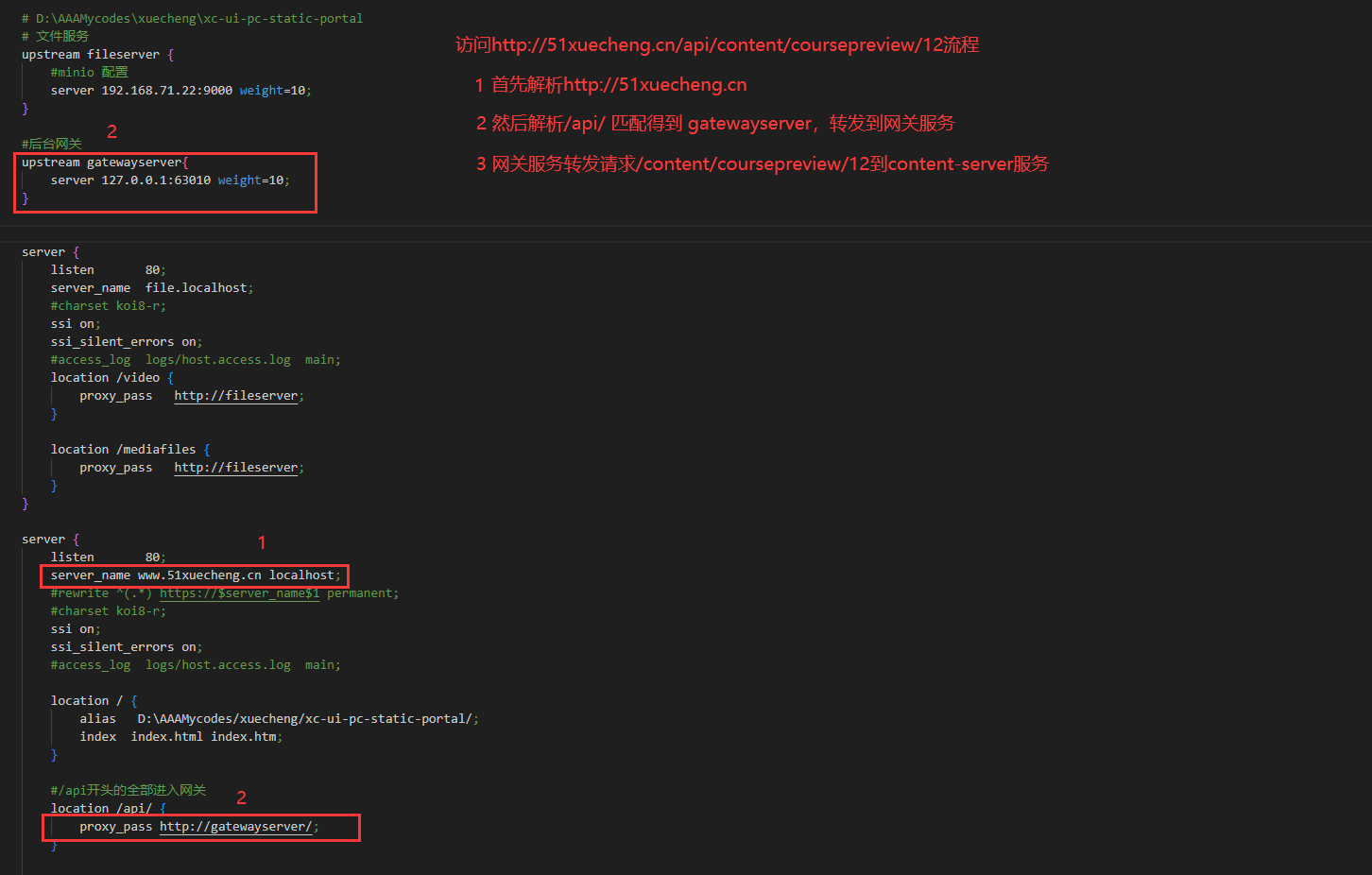
修改host
1 | 127.0.0.1 www.51xuecheng.cn 51xuecheng.cn ucenter.51xuecheng.cn teacher.51xuecheng.cn file.51xuecheng.cn group.51xuecheng.cn group1.xuecheng.com localhost |
编写freemarker模板
4.2 课程审核
- 学机构提交课程审核后,平台运营人员登录运营平台查询待审核的记录
- 具体审核的过程与课程预览的过程类似,运营人员查看课程信息、课程视频等内容
- 如果存在问题,则审核不通过,并附上审核不通过的原因供教学机构人员查看
- 如果课程内容没有违规信息且课程内容全面,则审核通过
课程审核通过后,教学机构发布课程成功
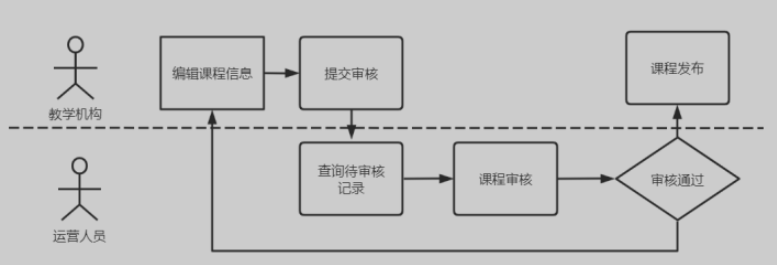
课程状态转移
<img src=(https://myl-mdimg.oss-cn-beijing.aliyuncs.com/TyporaImg/学成在线.assets/image-20240117101213845.png“ alt=”image-20240117101213845” style=”zoom:67%;” />
- 状态说明
- 一门课程新增后,它的审核状态为
未提交,发布状态为未发布 - 课程信息编辑完成,教学机构人员进行
提交审核操作,此时课程的审核状态为已提交 - 当课程状态为
已提交时,运营平台人员对课程进行审核 - 运营平台人员审核课程,结果有两个:审核通过、审核不通过
- 课程审核后不管状态是否通过,教学机构都可以再次修改课程并提交审核,此时课程状态为
已提交,运营平台人员再次审核课程 - 课程审核通过,教学机构人员可以发布课程,发布成功后,课程的发布状态为
已发布 - 课程发布后,通过
下架操作可以更改课程发布状态为下架 - 课程下架后,通过
上架操作可以再次发布课程,上架后课程发布状态为发布
- 一门课程新增后,它的审核状态为
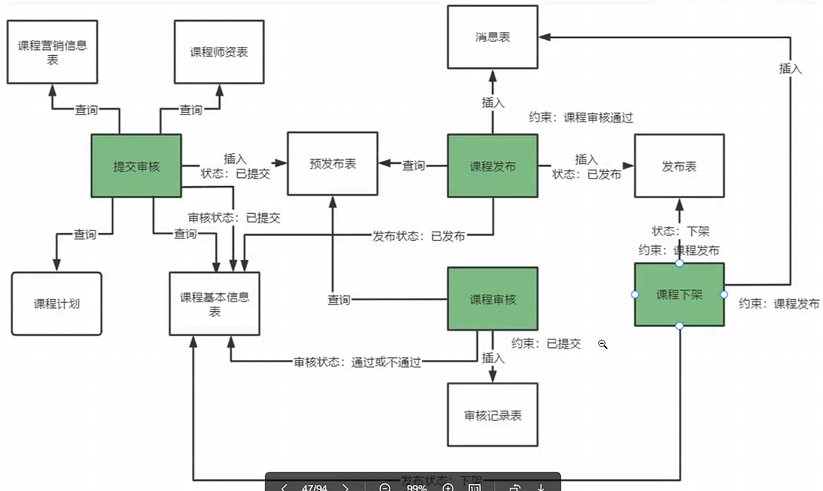
问题:课程审核通过后再修改,运营人员审核课程和教学机构编辑课程操作的数据是同一份,此时就可能产生冲突,例如:运营人员正在审核时,教学机构把数据修改了
- 为了解决这个问题,我们专门设计了一张课程与发布表
- 提交课程审核,将课程基本信息、营销信息、课程计划汇总后,写入该表中。
- 课程审核人员从预发布表查询信息
- 课程审核通过执行课程发布,将课程预发布的信息写入课程发布表
- 提交审核课程后,必须等待课程审核完毕后,才可以再次提交课程(无论审核通过/不通过)
- 为了解决这个问题,我们专门设计了一张课程与发布表
业务中的数据转移
4.3 课程发布
- 教学机构用户在课程管理中可对机构内课程进行检索
- 点击某课程数据后的发布连接,即可对该课程进行发布
- 课程发布后可通过课程搜索查询到的课程信息,查看课程的详细信息
- 点击课程搜索页中课程列表的某个课程,可以进入课程详情页
教学机构人员在课程审核通过后,即可发布课程,课程发布后会公开展示在网站上供学生查看、选课、学习
- 如何去快速搜索课程?打开课程详情页面仍然去查询数据库可行吗?
为了提高网站的速度需要将课程信息进行缓存,并且要将课程信息加入索引库方便搜索,下图显示了课程发布后课程信息的流转情况
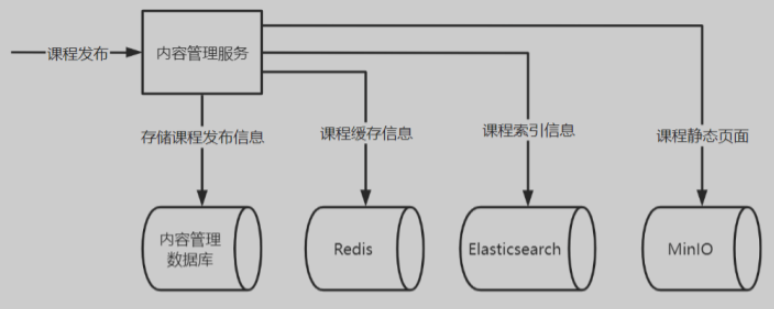
操作
- 向内容管理数据库的课程发布并存储课程发布信息
- 向Redis存储课程缓存信息
- 向Elasticsearch存储课程索引信息
- 请求分布式文件系统存储存储课程静态化页面(即htm页面),实现快速浏览课程详情页面
问题:一次课程发布操作需要向数据库、Redis、Elasticsearch、MinIO写四份数据,这里存在分布式事务问题
分布式事务
- 本地事务:平时我们在程序中通过Spring去控制事务是利用数据库本身的事务特性来实现的,因此叫
数据库事务,由于应用主要靠关系数据库来控制事务,而数据库通常和应用在同一个服务器,所以基于关系型数据库的事务又被称为本地事务。- 本地事务具有ACID四大特性
- 原子性(Atomicity):事务是一个不可分割的工作单位,事务中的操作要么全部成功,要么全部失败。
- 一致性(Consistency):事务在执行前后必须保持数据的一致性,即满足业务逻辑和约束条件。
- 隔离性(Isolation):事务之间不应相互干扰,每个事务都应该在独立的环境中执行,不受其他事务的影响。
- 持久性(Durability):事务一旦提交,其对数据的修改就应该永久保存在数据库中,即使发生系统故障或崩溃也不会丢失。
- 本地事务具有ACID四大特性
现在的需求是:课程发布操作后,将数据写入数据库、Redis、ElasticSearch、MinIO四个地方,这四个地方已经不限制在一个数据库内,而是由四个分散的服务去提供,与这四个服务去通信需要网络通信,而网络存在不可到达性(例如突然断网),在这种分布式系统环境下,通过与不同的服务进行网络通信去完成事务,称之为分布式事务
CAP理论是一个分布式系统设计的重要理论,它指出一个分布式系统最多只能同时满足一致性(Consistency)、可用性(Availability)和分区容忍性(Partition tolerance)这三项中的两项。
- 一致性是指所有节点访问同一份最新的数据副本
- 可用性是指每个请求都能得到响应
- 分区容忍性是指系统能够在网络分区的情况下继续运行。
- 所以CAP中要么保证CP要么保证AP
- CP的场景:满足C舍弃A,强调一致性
- 跨行转账:一次转账请求要等待双方银行系统都完成整个事务才算完成,只要其中一个失败,另一方执行回滚操作
- 开户操作:在业务系统开户同时要在运营商开户,任何一方开户失败,该用户都不可使用新开账户,要满足一致性
- AP的场景:满足A舍弃C,强调可用性(较多)
- 订单退款,今日退款成功,明日账户到账,只要用户可以接受在一定时间内到账即可
- 注册送积分,注册成功,积分在24小时内到账
- 支付短信通信,支付成功发短信,短信发送可以有延迟
- BASE理论:基于AP,是Basically Available(基本可用)、Soft state(软状态)和 Eventually consistent (最终一致性)三个短语的缩写
- 基本可用:当系统无法满足全部可用时,保证核心业务可用即可,比如一个外卖系统,到了饭点的时候系统并发量很高,此时要保证下单流程涉及的服务可用,其他服务暂不可用
- 软状态:可以存在中间状态,例如:微博的评论功能。当用户发表一条评论时,这条评论并不会立即同步到所有关注者的页面上,而是会先存储在缓存中,并逐渐传播到其他节点。这样就存在了一个中间状态,即某些用户可以看到这条评论,而某些用户还不能看到。
- 最终一致性:前面的软状态并不影响微博的整体可用性,用户仍然可以正常浏览和发表微博。最终,在一定时间内,所有关注者都能看到这条评论,达到了最终一致性。
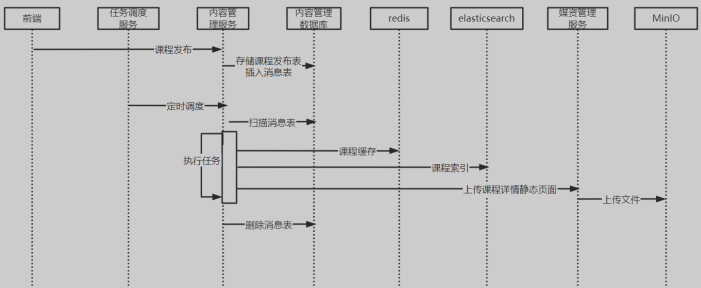
课程发布
课程发布的分布式事务控制:使用AP
课程发布操作后,先更新数据库中的课程发布状态,更新后向Redis、ElasticSearch、MinIO写课程信息,只要在一定时间内最终成功写入数据即可
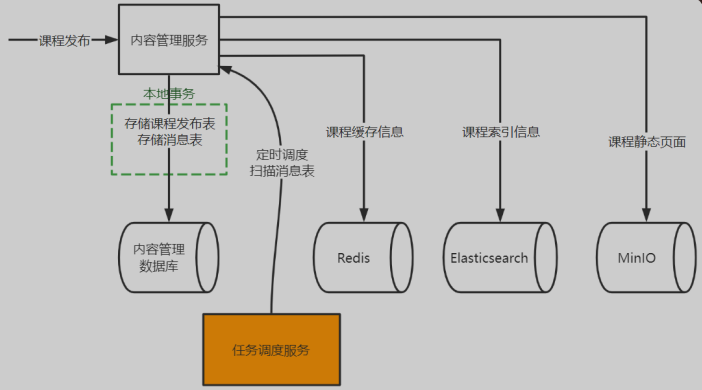
- 在内容管理服务的数据库添加一个消息表(mq_message),消息表和课程发布表在同一个数据库
- 点击课程发布,通过本地事务向课程发布表写入课程发布信息,同时向消息表写入课程发布的信息,这两条记录需保证同时存在或者同时不存在
- 启动任务调度系统的定时调度,内容管理服务去定时扫描消息表的记录
- 当扫描到课程发布的消息时,即开始向Redis、ElasticSearch、MinIO完成同步数据的操作
- 同步数据的任务完成后删除消息表记录,并插入历史消息表
时序图
消息处理SDK
- 课程发布操作执行后需要扫描消息表的记录,有关消息表处理的有哪些?
- 增删改查
- <img src=(https://myl-mdimg.oss-cn-beijing.aliyuncs.com/TyporaImg/学成在线.assets/image-20240117120836198.png“ alt=”image-20240117120836198” style=”zoom:60%;” />
问题:如果在每个地方都实现一套针对消息定时扫描、处理的逻辑,基本上都是重复的,软件的复用性太低、成本太高
解决:将消息处理相关的逻辑做成一个通用的东西,将消息处理做成一个SDK工具包,相比较通用服务,不仅可以解决将消息处理通用化的需求,还可以降低成本
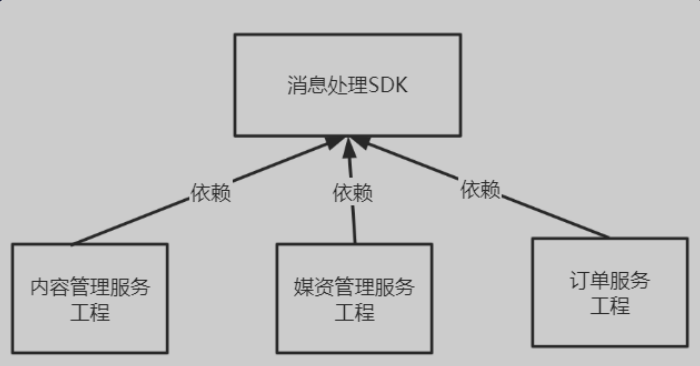
执行任务应该是SDK包含的功能吗?
- 拿课程发布任务举例,执行课程发布任务是要向Redis、索引库等同步数据,其他任务的执行逻辑是不同的,所以执行任务在SDK中不用实现,只需要提供一个抽象方法由具体的执行任务方去实现
如何保证任务的幂等性?
- 在视频处理章节介绍的视频处理的幂等性方案,这里可以采用类似方案
- 任务执行完成后,从消息表删除
- 如果消息表的状态是完成或不存在,则无需执行
- 在视频处理章节介绍的视频处理的幂等性方案,这里可以采用类似方案
如何保证任务不重复执行?
- 任务调度采用分片广播,根据分片参数去获取处理任务,配置调度过期策略为
忽略,配置任务阻塞处理策略为丢弃后续调度
- 任务调度采用分片广播,根据分片参数去获取处理任务,配置调度过期策略为
根据消息表记录是否存在或消息表中的任务状态去保证任务的幂等性,但是如果一个任务旗下又分为好几个小任务,例如课程发布任务需要执行3个同步操作:存储课程到Redis、存储课程到索引库、存储课程页面到MinIO。如果其中一个小任务已经完成,也不应该去重复执行这个小任务,那么该如何设计呢?
- 将小任务作为任务的不同阶段,在消息表中设立阶段状态
- 每完成一个阶段,就在对应的阶段状态字段打上标记,即使大任务还没有完成,重新执行大任务时,也会跳过执行完毕了的小任务
- 这里设立更多个小任务阶段状态字段为冗余字段,以备不时之需(万一你一个大任务下有10个小任务呢)
- 不过这里4个小任务状态字段就够了
页面静态化
- 根据课程发布的操作流程,执行课程发布后要将课程详情信息页面静态化,生成html页面上传至文件系统
什么是页面静态化?
- 课程预览功能通过模板引擎技术在页面模板中填充数据,生成html页面。这个过程是当客户端请求服务器时,服务器才开始渲染生成html页面,最终响应给浏览器,这个过程支持并发是有限的
- 页面静态化则强调将生成的html页面的过程提前,提前使用模板引擎技术生成html页面,当客户端请求时,直接请求html页面,由于是静态页面,可以使用nginx、apache等高性能web服务器,并发性能高
什么时候能用页面静态化技术?
- 当数据变化不频繁,一旦生成静态页面很长一段时间内很少变化,此时可以使用页面静态化。
- 因为如果数据变化频繁,一旦改变就需要重新生成静态页面,导致维护静态页面的工作量很大
- 根据课程发布的也无需求,虽然课程发布后仍可以修改课程信息,但是需要经过课程审核,且修改频率不高,所以适合使用页面静态化
feign远程调用
content-service添加feign依赖
nacos中配置feign并在content-service配置文件中引入
编写
MultipartSupportConfig类使feign支持Mulipart编写feign接口
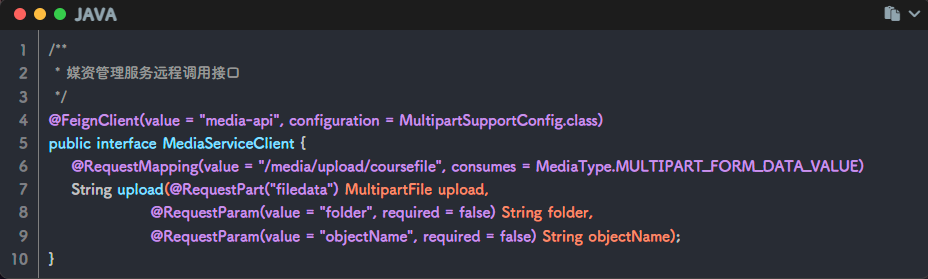
启动类添加
@EnableFeignClients注解
测试
熔断降级
当微服务运行不正常,会导致无法正常调用微服务,此时会出现异常,如果这种异常不去处理,可能会导致雪崩效应
微服务的雪崩效应表现在服务与服务之间调用,当其中一个服务无法提供服务时,可能导致其他服务也挂掉。
例如服务C调用服务B,服务B调用服务A,由于服务A异常导致服务B响应缓慢,最终导致服务A和服务B都不可用,而服务B不可用又导致服务C也不可用。
像这样由一个服务所引起的一连串的服务都无法提供服务,就是微服务的雪崩效应
<img src=(https://myl-mdimg.oss-cn-beijing.aliyuncs.com/TyporaImg/学成在线.assets/image-20240117165655380.png“ alt=”image-20240117165655380” style=”zoom:50%;” />
如何解决由于微服务异常所引起的雪崩效应呢?
- 采用熔断、降级的方法去解决
熔断降级的相同点都是为了解决微服务系统崩溃的问题,但它们是两个不同的技术手段,两者又存在联系
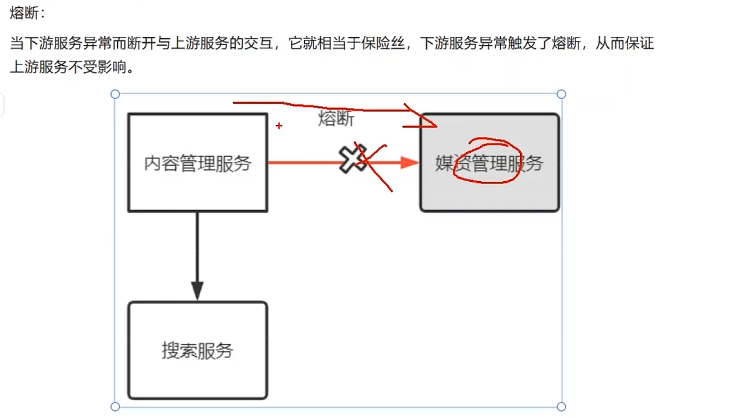
熔断:当下游服务异常时,断开与上游服务的交互。它就相当于保险丝,下游服务异常触发了熔断,从而保证上游服务不受影响
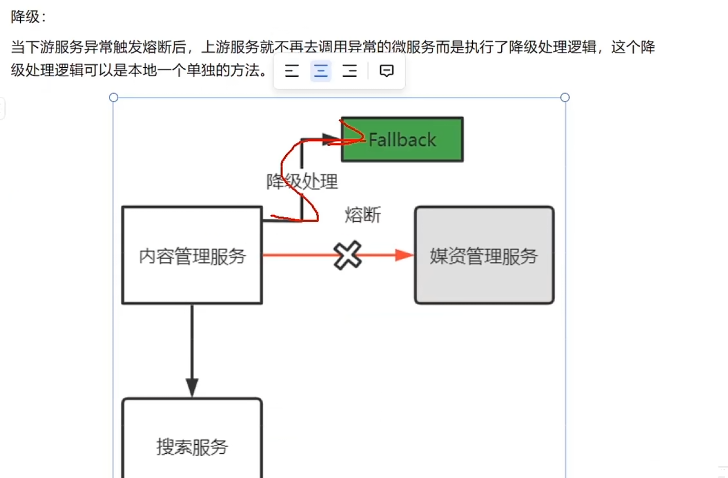
降级:当下游服务异常触发熔断后,上游服务就不再去调用异常的服务,而是执行降级处理逻辑,这个降级处理逻辑可以是本地的一个单独的方法
<img src=(https://myl-mdimg.oss-cn-beijing.aliyuncs.com/TyporaImg/学成在线.assets/image-20240117165816743.png“ alt=”image-20240117165816743” style=”zoom: 50%;” />
而这都是为了保护系统,熔断是当下服务异常时一种保护系统的手段,降级是熔断后上游服务处理熔断的方法
具体处理
开启feign熔断保护,在feign-dev.yaml中配置
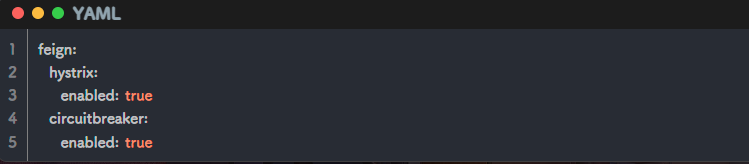
定义降级逻辑
- 方式一:fallback。定义一个fallback类
MediaServiceClientFallback,此类实现了MediaServiceClient接口
1
2
3
4
5
6
7
8
9
10/**
* 媒资管理服务远程调用接口
*/
public interface MediaServiceClient {
String upload( MultipartFile upload,
String folder,
String objectName);
}1
2
3
4
5
6
7
8
9
public class MediaServiceClientFallback implements MediaServiceClient{
public String upload(MultipartFile upload, String folder, String objectName) {
log.debug("方式一:熔断处理,无法获取异常");
return null;
}
}缺点:无法获取熔断的异常信息
- 方式二:fallbackFactory。由于方式一无法取出熔断所抛出的异常,而方式二定义MediaServiceClientFallbackFactory可以解决这个问题
1
2
3
4
5
6
7
8
9
10/**
* 媒资管理服务远程调用接口
*/
public interface MediaServiceClient {
String upload( MultipartFile upload,
String folder,
String objectName);
}1
2
3
4
5
6
7
8
9
10
11
12
13
14
public class MediaServiceClientFallbackFactory implements FallbackFactory<MediaServiceClient> {
public MediaServiceClient create(Throwable throwable) {
return new MediaServiceClient() {
public String upload(MultipartFile upload, String folder, String objectName) {
log.debug("方式二:熔断处理,熔断异常:{}", throwable.getMessage());
return null;
}
};
}
}- 方式一:fallback。定义一个fallback类
定义降级逻辑
- 返回一个null对象,上游服务请求接口得到一个null,说明执行了降级处理
4.4 课程搜索
es
参考文档:https://cyborg2077.github.io/2022/12/24/ElasticSearch/#RestAPI
主要过程
linux启动es,kibana(可视化管理)
创建mapping(类似于一个表,声明了有哪些列及属性)
- 转移到java项目中
- 初始化
RestHighLevelClient- 引入依赖
- 初始化RestHighLevelClient的Bean
- 使用
RestHighLevelClient
- 文档操作:
XxxIndexRequest,Xxx是Create、Get、Delete- 文档搜索:Search API
QueryBuilder用于构造搜索条件
课程信息索引同步
- 方案
- Canal(实时性高)
- 消息队列(实时性不高)
- 定时任务调度(xxlJob)
- 流程
- 课程发布向消息表中插入记录
- 由任务调度程序通过消息处理SDK对消息记录进行处理
- 向es索引中保存课程信息
5 认证授权模块
5.1 准备
- 认证授权模块实现平台所有用户的身份认证和用户授权功能
什么是用户身份认证?
- 用户身份认证即当用户访问系统资源时,系统要求验证用户的身份信息,身份合法方可继续访问
- 常见的用户身份认证表现形式有
- 用户名密码登录
- 微信扫码登录等
什么是用户授权?
- 用户认证通过后去访问系统的资源,系统会判断用户是否拥有访问资源的权限,只允许访问有权限的系统资源,没有权限的资源将无法访问,这个过程叫用户授权。
- 例如用户去发布课程,系统首先进行用户身份认证,认证通过后继续判断用户是否有发布课程的权限
- 如果没有权限,则拒绝继续访问系统
- 如果有权限,则继续发布课程
统一认证
包括学生、学习机构的老师、平台运营人员三类用户,三类用户将使用统一的认证入口
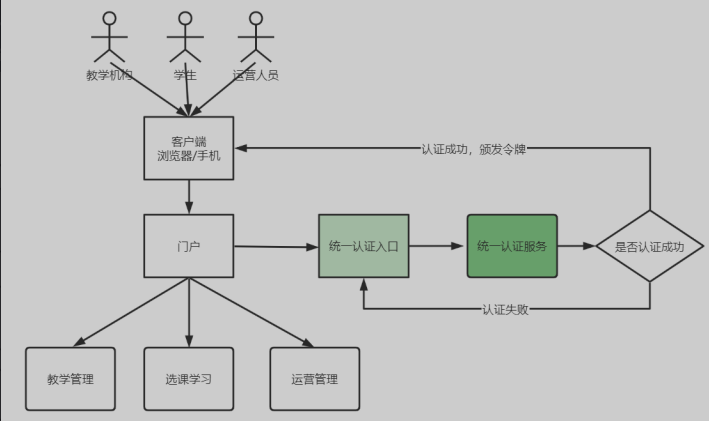
认证通过由认证服务想用户颁发令牌,相当于访问系统的通行证,用户拿着令牌去访问系统的资源
单点登录
- 本项目基于微服务架构构建,微服务包括:内容管理服务、媒资管理服务、系统管理服务等。
- 为了提高用户的体验性,用户只需要依次认证,便可以在多个拥有访问权限的系统中访问,这个功能叫单点登录
- 单点登录(Single Sign On),简称为 SSO,是目前比较流行的企业业务整合的解决方案之一。SSO的定义是在多个应用系统中,用户只需要登录一次就可以访问所有相互信任的应用系统。
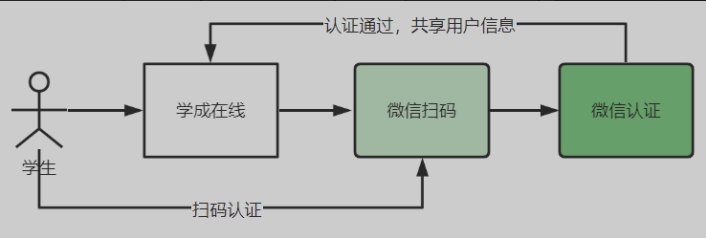
第三方认证
为了提高用户体验,很多网站都具有扫码登录的功能,例如微信扫码登录、QQ扫码登录等
扫码登录的好处是用户不用输入账号密码,操作简便,而且有利于用户信息的共享。
互联网的优势就是资源共享,用户也是一种资源,对于一个新网站,如果让用户去注册是很困难的,如果提供了微信扫码登录,将省去用户的注册成本,是一种非常有效的推广方式。
微信扫码登录其中的原理正是使用了第三方认证,如下图
Spring Security认证
认证功能几乎是每个项目都要具备的功能,并且它与业务无关,市面上有很多认证框架,如Apache Shiro、CAS、Spring Security等
本项目是基于Spring Cloud技术构建,Spring Security是spring家族的一份子,且和Spring Cloud集成的很好,所以本项目采用Spring Security作为认证服务的技术框架
SpringCloud Security:https://spring.io/projects/spring-cloud-security
Spring Security功能的实现主要是由一系列过滤器链相互配合完成的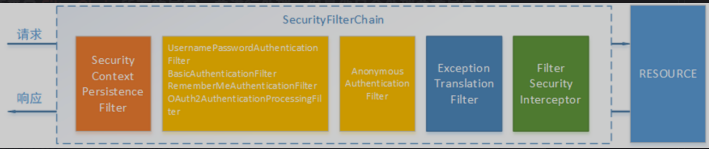
SecurityContextPresistenceFilter:这个Filter是整个拦截过程的入口和出口(也就是第一个和最后一个拦截器),会在请求开始时从配置好的SecurityContextRepository中获取SecurityContext,然后把它设置给SecurityContextHolder,在请求完成后,将SecurityContextRepository持有的SecurityContext再保存到配置好的SecurityContextRepository,同时清楚SecurityContextHolder所持有的SecurityContextUsernamePasswordAuthenticationFilter:用于处理来自表单提交的认证,该表单必须提供对应的用户名和密码,其内部还有登录成功或失败后进行处理的AuthenticationSuccessHandler和AuthenticationFailureHandler,这些都可以根据需求做相关改变FilterSecurityInterceptor是用于保护web资源的,使用AccessDecisionManager对当前用户进行授权访问ExeptionTranslationFilter能够捕获来自FilterChain所有的异常,并进行处理。但是他只会处理两类异常:AuthenticationException和AccessDeniedException,其他的异常它会继续抛出
执行流程
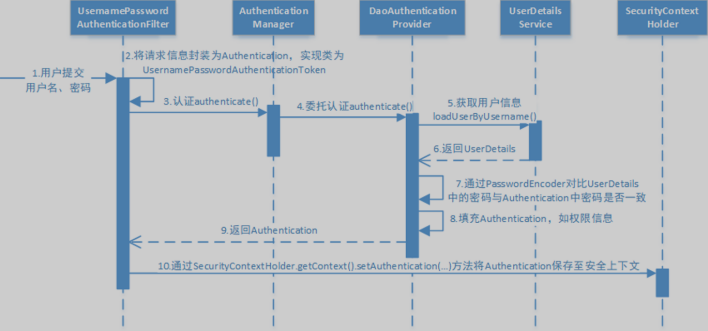
OAuth2协议
前面我们提到的微信扫码认证,是一种第三方认证方式,这种认证方式是基于OAuth2协议实现的
OAuth2认证微信扫码登录的过程
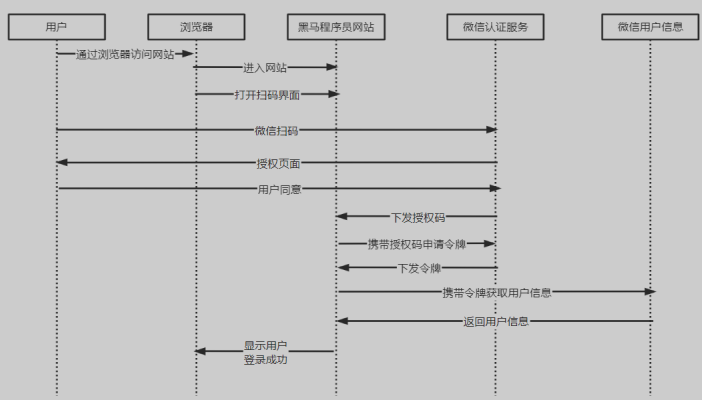
具体流程如下
- 用户点击微信扫码登录,微信扫码的目的是通过微信认证登录目标网站,目标网站需要从微信获取当前用户的身份信息才会让当前用户在目标网站登录成功
- 首先搞清楚几个概念
资源:用户信息,在微信中存储资源拥有者:用户是用户信息资源的拥有者认证服务:微信负责认证当前用户的身份,负责为客户端颁发令牌客户端:客户端会携带令牌请求微信获取用户信息
- 首先搞清楚几个概念
- 用户授权网站访问用户信息
- 资源拥有者扫描二维码,表示资源拥有者请求微信进行认证,微信认证通过向用户手机返回授权页面(让你确认登录)
- 询问用户是否授权目标网站访问自己在微信的用户信息,用户点击(确认登录)表示同意授权,微信认证服务器会颁发一个授权码给目标网站
- 只有资源拥有者同意,微信才允许目标网站访问资源
- 目标网站获取到授权码
- 携带授权码请求微信认证服务器,申请令牌(此交互过程用户看不到)
- 微信认证服务器想目标网站响应令牌(此交互过程用户看不到)
- 目标网站携带令牌请求微信服务器获取用户的基本信息
- 资源服务器返回受保护资源,即用户信息
- 目标网站接收到用户信息,此时用户在目标网站登录成功
- 用户点击微信扫码登录,微信扫码的目的是通过微信认证登录目标网站,目标网站需要从微信获取当前用户的身份信息才会让当前用户在目标网站登录成功
OAuth2.0认证流程
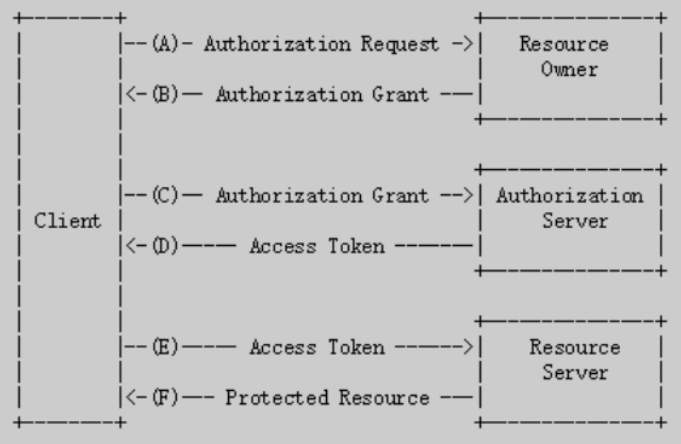
A表示:客户端请求资源拥有者授权B表示:资源拥有者授权客户端,即用户授权目标网站访问自己的用户信息C表示:目标网站携带授权码请求认证D表示:认证通过,颁发令牌E表示:目标网站携带令牌请求资源服务器,获取资源F表示:资源服务器校验令牌通过后,提供受保护的资源
OAuth 2.0包括以下角色
客户端:本身不存储资源,需要通过资源拥有者的授权去请求资源服务器的资源,例如:手机客户端、浏览器等资源拥有者:通常为用户,也可以是应用程序,即该资源的拥有者授权服务器(认证服务器):认证服务器对资源拥有者进行认证,还会对客户端进行认证并颁发令牌资源服务器:存储资源的服务器
在本项目的应用
- 学成在线访问第三方系统的资源
- 本项目要接入微信扫码登录,所以本项目要是用OAuth2协议访问微信中的用户信息
- 外部系统访问学成在线的资源
- 同样当第三方系统想要访问学成在线网站的资源,也可以基于OAuth2协议来访问用户信息
- 学成在线前端(客户端)访问学成在线微服务的资源
- 本项目是前后端分离架构,前端访问微服务资源也可以基于OAuth2协议
- 学成在线访问第三方系统的资源
四种模式
授权码模式(微信扫码)
<img src=(https://myl-mdimg.oss-cn-beijing.aliyuncs.com/TyporaImg/学成在线.assets/image-20240118172500362.png“ alt=”image-20240118172500362” style=”zoom:67%;” />
密码模式(也应用的多)
<img src=(https://myl-mdimg.oss-cn-beijing.aliyuncs.com/TyporaImg/学成在线.assets/image-20240118172522851.png“ alt=”image-20240118172522851” style=”zoom:67%;” />
简化模式
客户端模式
JWT
普通令牌问题
客户端申请到令牌,接下来客户端携带令牌去访问资源,到资源服务器会校验令牌的合法性。
资源服务器如何校验令牌的合法性?这里以OAuth2的密码模式为例进行说明<img src=(https://myl-mdimg.oss-cn-beijing.aliyuncs.com/TyporaImg/学成在线.assets/image-20240119094718731.png“ alt=”image-20240119094718731” style=”zoom:50%;” />
问题:校验令牌需要远程请求认证服务,客户端每次访问都会远程校验,执行性能低
改进:
<img src=(https://myl-mdimg.oss-cn-beijing.aliyuncs.com/TyporaImg/学成在线.assets/image-20240119094817784.png“ alt=”image-20240119094817784” style=”zoom:50%;” />
如何解决上面的问题,实现资源服务自行校验令牌呢?
- 令牌采用JWT格式即可解决上面的问题,用户认证后会得到一个JWT令牌,JWT令牌中已经包括了用户相关的信息,客户端只需要携带JWT访问资源服务,资源服务根据事先约定的算法自行完成令牌校验,无需每次都请求认证服务完成授权
Json Web Token(JWT)是一种使用Json格式传递数据的网络令牌技术,它是一个开放的行业标准(RFC 7519),它定义了一种简介的、自包含的协议格式,用于在通信双方传递Json对象,传递的对象经过数字签名可以被验证和信任,它可以是应用HMAC算法或使用RSA的公钥/私钥来签名,防止内容篡改https://jwt.io/
- 使用JWT可以实现无状态认证。什么是
无状态认证? - 传统的基于Session的方式是
有状态认证,用户登录成功,将用户的身份信息存储在服务端,这样加大了服务端的存储压力,并且这种方式不适合在分布式系统中应用- 当用户访问应用服务,每个应用服务都会去服务器查看Session信息,如果没有Session,则认证用户没有登录,此时会重新认证,而解决这个问题的颁发是Session复制黏贴
- 如果是基于令牌技术,用户,用户将令牌存储在客户端,去访问应用服务时携带令牌去访问,服务端从JWT解析出用户信息,这个过程就是无状态认证
- 使用JWT可以实现无状态认证。什么是
- JWT令牌的优点
- JWT基于JSON,非常方便解析
- 可以在令牌中自定义丰富的内容,易扩展
- 通过非对称加密算法及数字签名技术,JWT防篡改,安全性高
- 资源服务使用JWT可不依赖认证服务即可完成授权
缺点
- JWT令牌较长,占存储空间比较大
JWT内容:有三部分,每部分中间使用点(.)分隔,例如xxxx.yyyyyy.zzzzzzz
第一部分Header:头部包括令牌的类型(即JWT)及使用的哈希算法(如HMAC、SHA256或RSA),一个例子如下
1
2
3
4{
"alg": "HS256",
"typ": "JWT"
}- 将上面的内容使用Base64Url编码,得到一个字符串就是JWT令牌的第一部分
第二部分Payload:内容也是一个Json对象
它是存放有效信息的地方,它可以存放JWT提供的现成字段,如iss(签发者)、exp(过期时间戳)、sub(面向的用户)等,也可以自定义字段
此部分不建议存放敏感信息,因为此部分可以解码还原原始内容
最后将第二部分负载使用Base64Url编码,得到一个字符串就是JWT令牌的第二部分
1
2
3
4
5{
"sub": "1234567890",
"name": "456",
"admin": true
}
第三部分:Sugbature:第三部分是签名,此部分用于防止JWT内容被篡改。
这个部分使用Base64Url将前两部分进行编码,编码后使用点(.)连接组成字符串,最后使用Header中声明的签名算法进行签名
1
2
3
4HMACSHA256(
base64UrlEncode(header) + "." +
base64UrlEncode(payload),
secret)
为什么JWT可以防止篡改?
- 第三部分使用签名算法对第一部分和第二部分的内容进行签名,常见的签名算法是HS526,常见的还有MD5、SHA等,签名算法需要使用密钥进行签名,密钥不对外公开,并且签名是不可逆的,如果第三方更改了内容,那么服务器验证前面就会失败,要想保证签名正确,必须保证内容、密钥与签名前一致
JWT认证过程
<img src=(https://myl-mdimg.oss-cn-beijing.aliyuncs.com/TyporaImg/学成在线.assets/image-20240119095547079.png“ alt=”image-20240119095547079” style=”zoom:67%;” />
- 从上图中可以看出,认证服务和资源服务使用相同的密钥,这叫对称加密,对称加密效率高,如果一旦密钥泄露可以伪造JWT令牌
- JWT还可以使用非对称加密,认证服务自己保留私钥,将公钥下发给受信任的客户端、资源服务,公钥和私钥是配对的,成对的公钥和私钥才可以正常加密、解密,非对称加密效率低,但相比较于对称加密更加安全
网关鉴定
加上网关后的过程
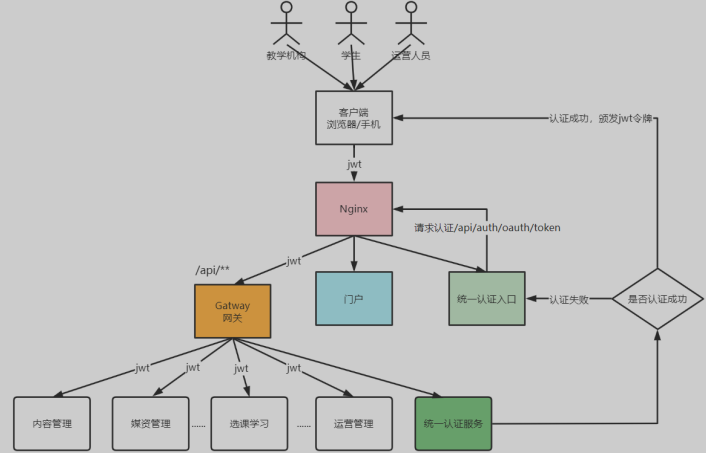
所有访问微服务的请求都要经过网关,在网关进行用户身份的认证,可以将很多非法的请求拦截到微服务以外,这叫做网关鉴权
网关鉴权的职责
- 网站白名单维护:针对不用认证的URL全部放行
校验JWT的合法性:除了白名单剩下的就是需要认证的请求,网关需要验证JWT的合法性,JWT合法则说明用户身份合法,否则说明身份不合法,拒绝继续访问
注意:网关不负责授权,对请求的授权操作在各个微服务进行,因为微服务最清楚用户有哪些权限访问哪些接口
步骤
- 在网关服务中引入依赖
- 网关过滤器
- 配置白名单
- 在微服务中放行所有请求
5.2 用户认证
到目前为止,我们的用户认证流程如下
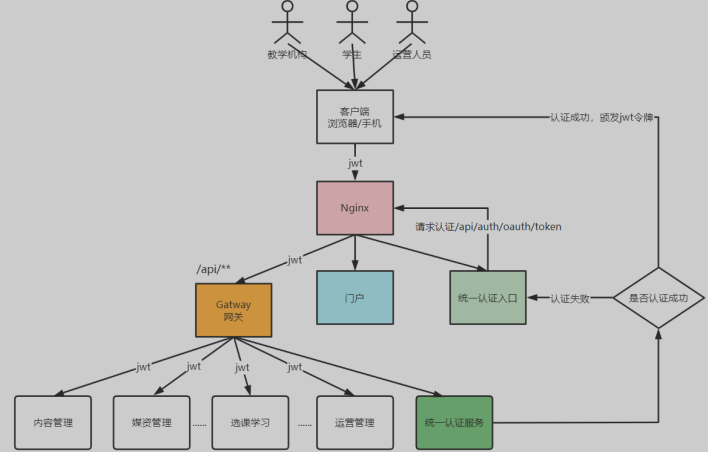
自定义
UserDetailsImpl implements UserDetailsService读取数据库用户信息- 重写
loadUserByUsername()方法
- 重写
扩展用户身份信息,在JWT令牌中存储用户的昵称、头像、QQ等信息
- 说明:在认证阶段DaoAuthenticationProvider会调用UserDetailsService查询用户的信息,这里是可以获取到齐全的用户信息,由于JWT令牌中用户身份信息来源于UserDetails,UserDetails中仅定义了username为用户的身份信息,这里有两个思路
- 方法一:自定义
UserDetails,让它包括更多的自定义属性 - 方法二:扩展username的内容,例如存入Json数据作为username的内容
资源服务获取用户身份
- 根据返回的json内容转为一个java对象
- 在content-api中定义一个工具类来处理
5.3 统一认证服务
基于当前研究的Spring Security认证流程如何支持多样化的认证方案呢?
- 支持账号和密码认证
- 采用OAuth2协议的密码模式即可实现
- 支持手机号加验证码认证
- 用户认证提交的是手机号和验证码,并不是账号和密码
- 微信扫码认证
- 基于OAuth2协议与微信交互,学成在线网站会向微信服务器申请一个令牌,然后携带令牌去微信查询用户信息,查询成功则用户在学成在线项目认证通过
而不同的认证提交方式的数据不一样,例如
- 手机加验证码方式:会提交手机号和验证码
- 账号密码方式:会提交账号、密码、验证码
解决:我们可以在
loadUserByUsername()方法上做文章,将用户原来提交的账号数据改为提交一个JSON数据,JSON数据可以扩展不同的认证方式所提交的各种参数步骤
定义
AuthParamsDto来接收认证参数(统一接收参数)修改
UserDetailsImpl的loadUserByUsername()方法,让它解析接收的字符串为AuthParamsDto对象(之前就只是一个密码)- 继承
DaoAuthenticationProvider并重写additionalAuthenticationChecks方法 - 在
WebSecurityConfig中注入 - 定义
AuthService接口,不同的登录方式分别继承这个接口,重写execute方法(策略模式) - 修改
UserDetailsImpl的loadUserByUsername,根据输入参数转换的AuthParamsDto对象的authType方法来获取到spring容器的AuthService继承类的bean,调用bean的execute方法得到XcUserExt对象,随后转为Json返回(主要要把敏感信息置null,比如密码)
总结:
- 统一在一个地方登录
- 统一请求数据/认证参数
- 统一了认证接口
5.4 验证码服务
- 步骤
- 请求生成验证码:
POST {{checkcode_host}}/checkcode/pic - 返回一个json 包含
key和aliasing两个字段,key表示验证码的key,aliasing是对应的图片,与此同时将key和对应的验证码字符串存入redis中,其中键就是key,值就是字符串 - 当用户进行验证码验证的时候,根据key向redis中取出字符串进行对比
- 请求生成验证码:
5.5 账号密码登录完善
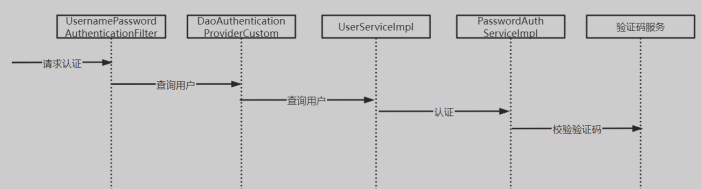
- 前期准备完成
- 步骤
- 定义远程调用验证码服务的接口
- 启动类添加开启Feign的注解
- 完善
PasswordAuthServiceImpl
5.6 微信登录(与第三方接口对接)
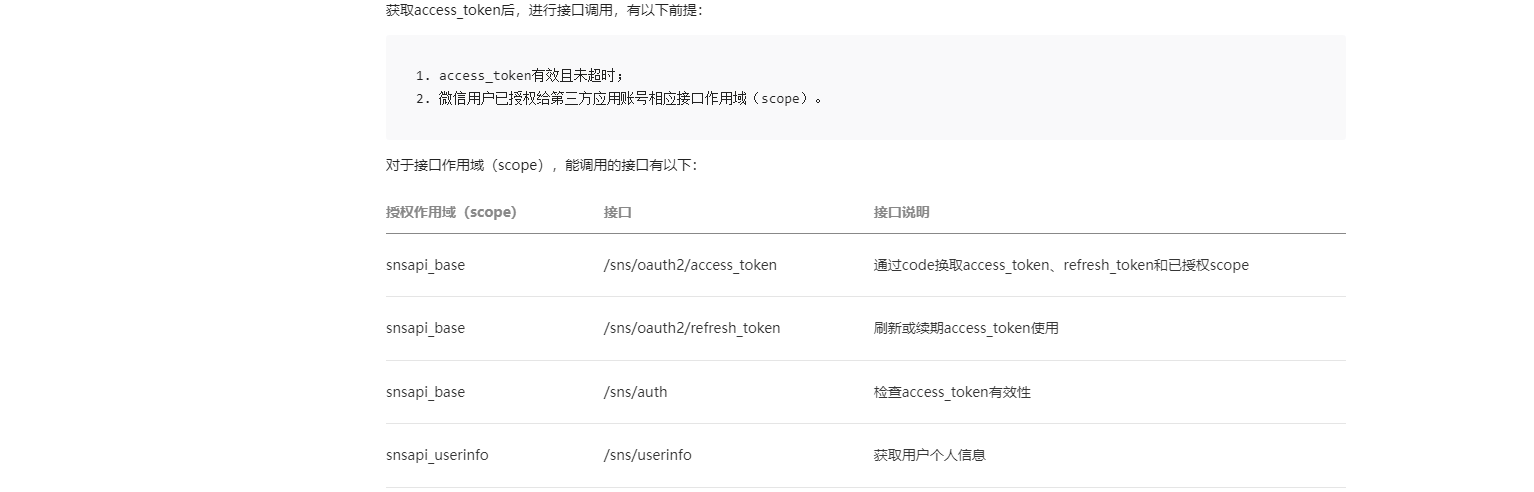
接口文档:https://developers.weixin.qq.com/doc/oplatform/Website_App/WeChat_Login/Wechat_Login.html
整体流程:
第三方发起微信授权登录请求,微信用户允许授权第三方应用后,微信会拉起应用或重定向到第三方网站,并且带上授权临时票据 code 参数;

通过 code 参数加上 AppID 和AppSecret等,通过 API 换取access_token(令牌);

通过access_token进行接口调用,获取用户基本数据资源或帮助用户实现基本操作。
<img src=(https://myl-mdimg.oss-cn-beijing.aliyuncs.com/TyporaImg/学成在线.assets/image-20240119151437866.png“ alt=”image-20240119151437866” style=”zoom:67%;” />
结合本项目流程
<img src=(https://myl-mdimg.oss-cn-beijing.aliyuncs.com/TyporaImg/学成在线.assets/image-20240119152008978.png“ alt=”image-20240119152008978” style=”zoom:67%;” />
本项目认证服务需要做哪些事?
- 需要定义接口接收微信下发的授权码
- 收到授权码调用微信接口申请令牌
- 申请到令牌后,调用微信获取用户信息
- 获取用户信息成功,将其写入本项目的用户信息数据库
- 重定向到浏览器自动登录
- 需要一个内网穿透工具,不然微信服务无法找到本机的认证服务
5.7 授权
- 如何实现授权?业界通常基于RBAC实现授权
RBAC
- 两种方式
- 基于角色的访问控制(Role-Based Access Control):按角色进行授权
- 缺点:当需要修改角色权限时,就需要修改授权相关的代码,系统可扩展性差
- 基于资源的访问控制(Resource-Based Access Control):按资源/权限授权
- 系统设计时定义好权限标识,修改角色的权限信息即可完成角色权限
- 基于角色的访问控制(Role-Based Access Control):按角色进行授权
资源服务授权流程
本项目在资源服务内部进行授权,基于资源的授权方式,因为接口在资源服务,通过在接口处添加授权注解实现授权
配置nginx
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20#前端开发服务
upstream uidevserver{
server 127.0.0.1:8601 weight=10;
}
server {
listen 80;
server_name teacher.localhost;
ssi on;
ssi_silent_errors on;
location / {
proxy_pass http://uidevserver;
proxy_cookie_path / "/; HTTPOnly; SameSite=strict";
proxy_cookie_domain uidevserver teacher.localhost;
}
location /api/ {
proxy_pass http://gatewayserver/;
}
}接口中使用:
@PreAuthorize("hasAuthority('权限标识符')")原理:在令牌中有一个
authorities字段表示用户的权限信息,然后去和@PreAuthorize注解中的权限进行对比,在权限范围则通过,否则拒绝
数据模型
- 如何给用户分配权限呢?查看数据库中的表结构
xc_user:用户表,存储了系统用户信息xc_user_role:用户角色表,一个用户可拥有多个角色,一个角色可被多个用户拥有- 关系表,用于连接
xc_user和xc_role
- 关系表,用于连接
xc_role:角色表,存储了系统的角色类型,角色类型包括:学生、老师、管理员、教学管理员、超级管理员xc_permission:角色权限表,一个角色可拥有多个权限,一个权限可被多个角色拥有- 关系表,用于连接
xc_role和xc_menu表
- 关系表,用于连接
xc_menu:权限菜单表,里面记录了各种操作的权限code
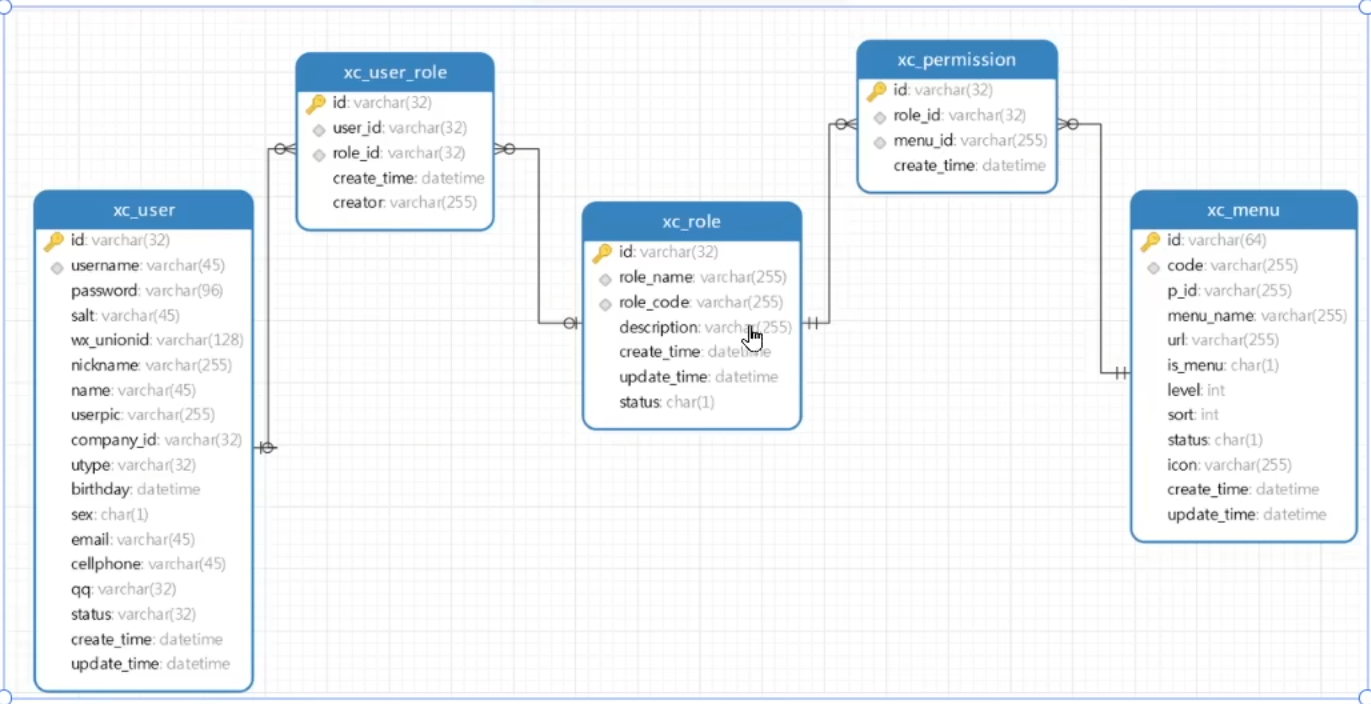
- 如何将用户的权限返回?
- UserDetails构建的时候加入
authorities的修饰
- UserDetails构建的时候加入
- 查询用户权限
5.8 细粒度授权
什么叫细粒度授权?
- 细粒度授权也叫数据范围授权,即不同的用户所拥有的的操作权限相同,但是能够操作的数据范围是不一样的。
- 例如:用户A和网易的,用户B是字节的,他们都拥有
我的课程的权限,但他们查询到的数据是不一样的,因为不能查询别的机构的课程本项目有哪些细粒度授权?
- 我的课程:教学机构只允许查询本机构下的课程信息
- 我的选课:学生只允许查询自己所选的课
如何实现细粒度授权?
- 细粒度授权涉及到不同的业务逻辑,通常在service层实现,根据不同的用户进行校验,根据不同的参数查询不同的数据,或操作不同的数据
实现
- 教学机构在维护课程时,只允许维护本机构的课程,教学机构细粒度授权过程如下
- 获取当前登录的用户身份
- 得到用户所属教育机构的id
- 查询该教学机构下的课程信息
- 最终实现了用户只允许查询自己机构的课程信息
- 在之前的做法,我们是模拟了一个假数据,用的是一个写死的companyId
- 根据companyId查询课程,流程如下
- 教学机构用户登录系统,从用户身份中取出所属机构的id
- 接口层取出当前登录用户的身份,取出机构id
- 将机构id传入service方法
- service方法将机构id传入dao方法,作为SQL查询参数(where companyId = ${companyId}),最终查询出本机构的课程信息
6 选课模块
6.1 学生选课
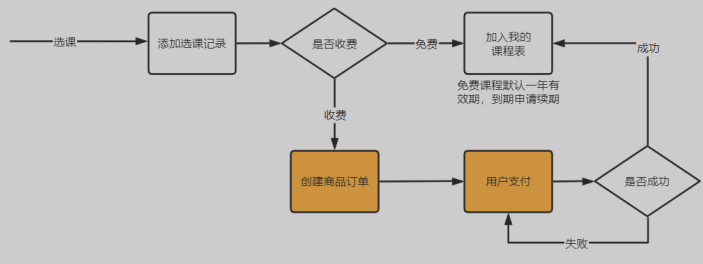
选课信息存入选课记录表
- 如果选的是免费课程,除了要将信息存入选课记录表,同时也要存入我的课程表
- 如果选的是收费课程,将信息存入选课信息表后,要经过下单、支付成功后,才可以存入我的课程表
选课记录表
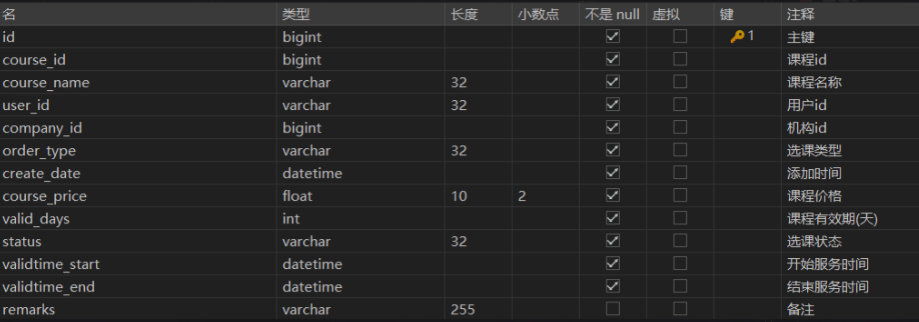
- 选课类型:免费课程、收费课程
- 选课状态:选课成功、待支付、选课删除
- 对于免费课程:课程价格为0,默认有效期为365天,开始服务时间为选课时间,结束服务时间为选课时间加一年后的时间,选课状态为选课成功
- 对于收费课程:按课程的现价、有效期确定开始服务时间、结束服务时间、选课状态为待支付
- 收费课程的选课记录需要支付成功后,选课状态为选课成功
我的课程表
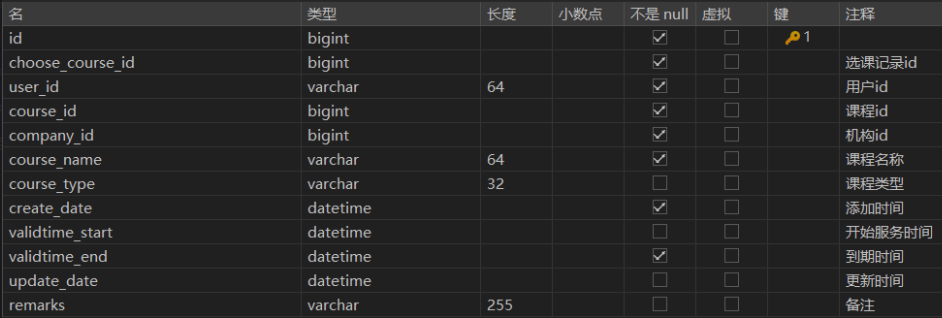
- 对于免费课程:创建选课记录时,同时向我的课程表添加记录
- 对于收费课程:创建选课记录后,需要下单支付成功后,自动向我的课程表添加记录
具体流程
<img src=(https://myl-mdimg.oss-cn-beijing.aliyuncs.com/TyporaImg/学成在线.assets/image-20240123092958882.png“ alt=”image-20240123092958882” style=”zoom:67%;” />
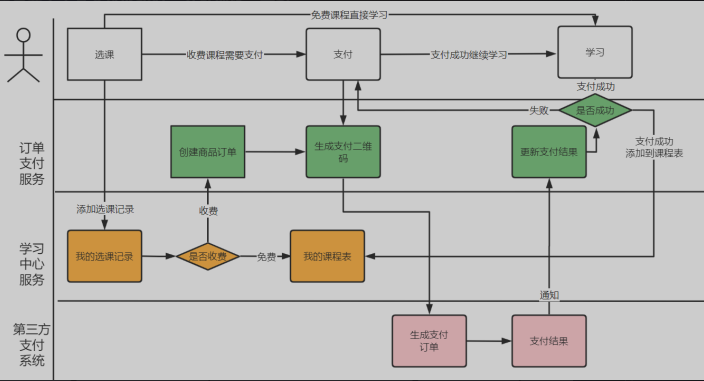
6.2 下单支付
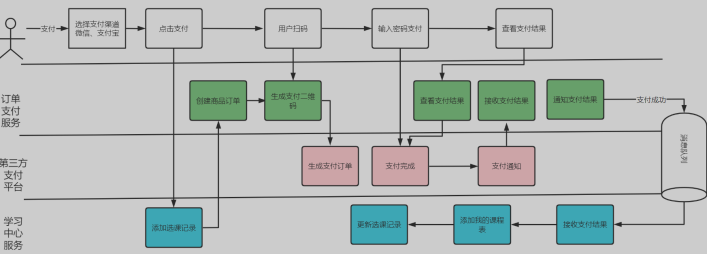
- 流程(红色部分是订单支付模块完成)
- 请求学习中心服务创建选课记录
- 请求订单服务创建商品订单、生成支付二维码
- 用户扫码请求订单支付服务,订单支付服务请求第三方支付平台生成支付订单
- 前端唤起支付客户端,用户输入密码完成支付
- 第三方支付平台支付完成后,发起支付通知
- 订单支付服务接收支付通知结果
- 用户在前端查询支付结果,请求订单支付服务查询支付结果,如果订单服务还没有收到支付结果,则请求学习中心查询支付结果
- 订单支付服务向学习中心通知支付结果
- 学习中心服务收到支付结果,如果支付成功则更新选课记录,并添加到我的课程表
6.3 支付通知
- 支付服务通过消息队列将支付消息给学习服务
为什么不用feign?
- 减少耦合
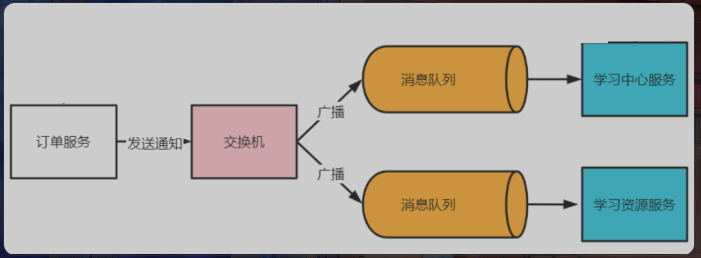
- 订单服务作为通用服务,在订单支付成功后,需要将支付结果异步通知给其他微服务
- 学习中心服务:对于收费课程,选课需要支付,与订单服务对接完成支付
- 学习资源服务:对于收费的学习资料,需要购买后才能下载,与订单服务对接完成支付
- 本项目使用RabbitMQ,可以通过以下几个方面保证消息的可靠性
- 生产者确认机制
- 发送消息前,使用数据库事务将消息保证到数据库表中
- 成功发送到交换机,将消息从数据库中删除
- MQ持久化
- MQ收到消息会持久化,当MQ重启,即使消息没有消费完,也不会丢失
- 需要配置交换机持久化、队列持久化、发送消息时设置持久化
- 消费者确认机制
- 消费者消费成功,自动发送ACK,负责重试消费
- 生产者确认机制
6.4 学生学习
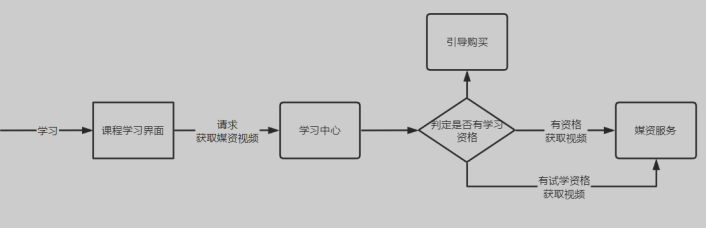
- 用户通过课程详情界面点击
马上学习,进入视频播放页面进行视频点播 - 获取视频资源时,进行学习资格校验
- 拥有学习资格则继续播放视频,不具有学习资格,则引导其去购买、续期等操作
如何判断是否拥有学习资格?
- 首先判断是否为试学视频,如果为试学视频,则可以正常学习
- 如果为非试学视频,则先判断用户是否登录,如果已经登录则判断是否选课,如果已经选课,且没有过期则可以正常学习
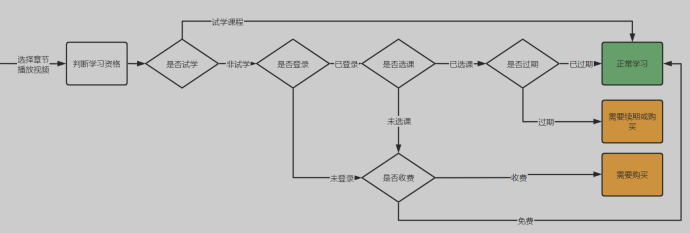
6.5 我的课程表
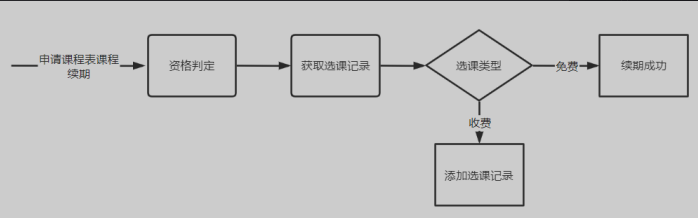
6.6 免费课程续期
7 支付模块
配置沙箱环境
接口交互流程
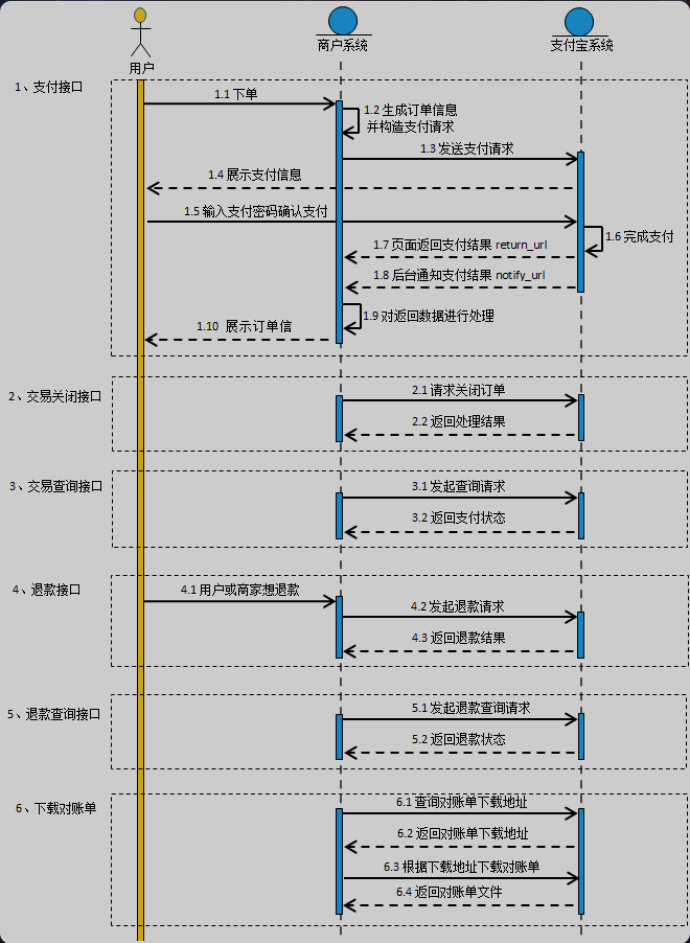
7.1 接口测试
查文档
7.2 生成二维码
<img src=(https://myl-mdimg.oss-cn-beijing.aliyuncs.com/TyporaImg/学成在线.assets/image-20240123162041937.png“ alt=”image-20240123162041937” style=”zoom: 67%;” />
- 流程
- 前端调用学习中心服务的添加选课接口
- 添加选课成功,请求订单服务生成支付二维码接口
- 生成二维码接口:创建商品订单、生成支付交易记录、生成二维码
- 将二维码返回到前端,用户扫码
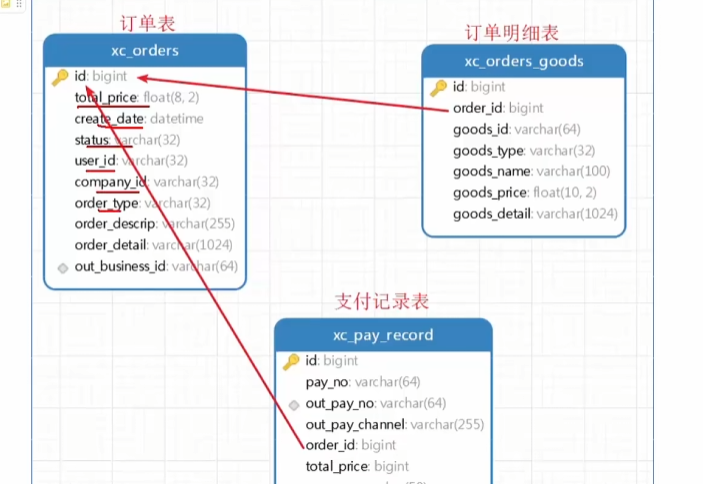
- 其中支付记录表的pay_no才是传给支付平台的订单号
为什么创建支付交易记录?
在请求微信或支付宝下单接口时,需要传入
商品订单号,在与第三方交付平台对接时发现,当用户支付失败或因为其他原因导致该订单没有支付成功,此时再次调用第三方支付平台的下单接口就会报错订单号已存在。但如果我们此时传入一个新的订单号就可以解决问题,但是商品订单已经创建,因此没有支付成功重新创建一个新订单是不合理的
解决以上问题的方案是
用户每次发起都创建一个新的支付交易记录,此交易记录与商品订单关联
将支付交易记录的流水号传给第三方支付系统的下单接口,这样即使没有支付成功,也不会出现上面的问题
判断订单支付状态,提醒用户不要重复支付

8 项目部署
DevOps(Development 和 Operations)

CI/CD包含两个CI和两个CD
- 持续集成
- 持续交付
- 持续部署
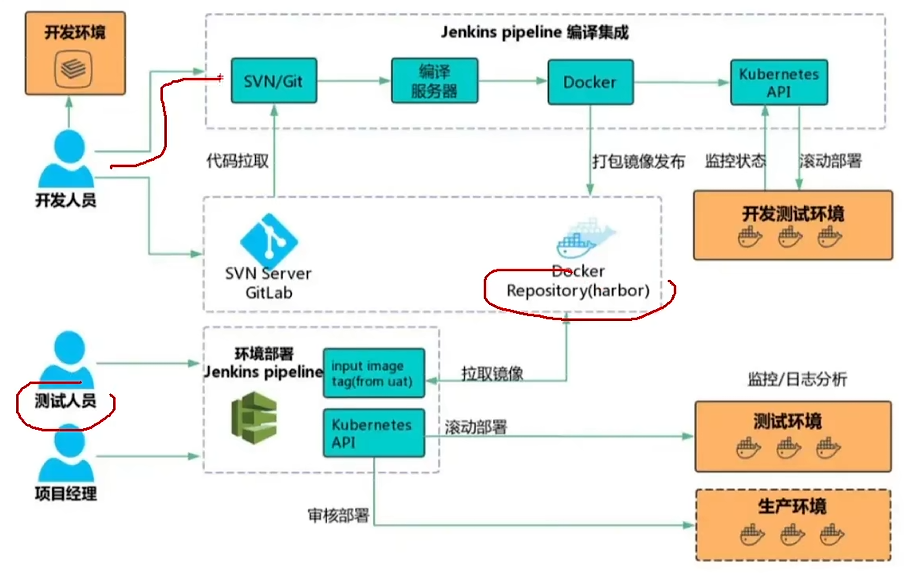
- Kubernetes:k8s(中间有8个字母)
- Jenkins
环境准备
Centos7虚拟机,安装docker、jdk、maven,通过docker容器安装jenkins、docker私服软件及其他软件
手动部署
项目打包
在parent项目的pom中聚合各个模块
<img src=(https://myl-mdimg.oss-cn-beijing.aliyuncs.com/TyporaImg/学成在线.assets/image-20240124161607063.png“ alt=”image-20240124161607063” style=”zoom:67%;” />
这样做的好处是之后编译的时候maven会自动识别依赖关系然后自动确定各个模块的打包顺序
配置打包插件

在要打可执行jar包的工程中配置该插件
说明

package生成jar包,使用
java -jar可以正常启动运行然后传到linux中,并在文件夹中创建dockerfile文件用于构建镜像

使用docker build创建镜像
1
docker build -t checkcode:1.0 .
-t checkcode:1.0是指构建后的镜像名称- 最后的
.表示dockerfile文件在当前目录
创建并启动容器
1
docker run --name xuecheng-plus-checkcode -p 63075:63075 -idt checkcode:1.0
查看运行日志
1
docker logs -f xuecheng-plus-checkcode
自动部署Jenkins
- 修改需要启动的服务的pom文件
- 代码提交到git
9 项目优化
压力测试
主要是测试需要直接查询数据库的地方,比如课程信息中的视频就是直接查数据库来的
吞吐量(TBS):系统每秒可以处理的事务数
- 响应时间:指客户端请求数据,请求从系统到客户端的时间
- 每秒查询数(QPS):一秒可以请求该接口查询商品信息的次数
- 错误率
Jmeter软件
9.1 redis缓存优化
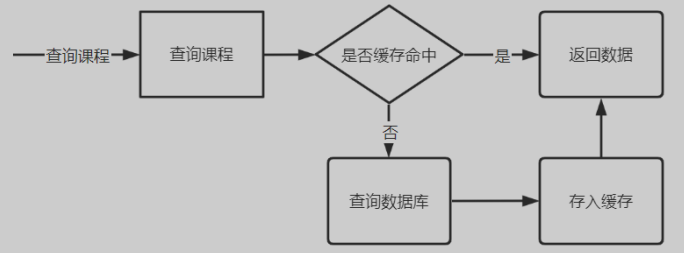
实现
<img src=(https://myl-mdimg.oss-cn-beijing.aliyuncs.com/TyporaImg/学成在线.assets/image-20240125104730079.png“ alt=”image-20240125104730079” style=”zoom:67%;” />
缓存穿透问题
使用缓存后,码的性能有了很大的提升,但是控制台还是打出了很多从数据库查询的日志,明明已经判断了如果缓存存在,课程信息就从缓存中查询,那为什么还有这么多从数据库查询的请求呢?
- 因为并发数很高,很多线程会同时到达查询数据库代码处去执行
- 如果存在恶意攻击的可能,大量并发去查询一个不存在的课程信息会出现什么问题呢?
- 大量并发去访问一个数据库不存在的数据,由于缓存中没有该数据,就会导致大量并发查询数据库,这个现象叫缓存穿透
- 缓存穿透可以造成数据库瞬间压力过大,连接数等资源耗尽,最终数据库拒绝连接,不可用
缓存穿透解决
- 方式一:对请求增加校验极致
- 方式二:使用布隆过滤器
- 方式三:缓存空值或特殊值
- 请求通过了第一步校验,查询数据库得到的数据不存在,此时我们仍然去缓存数据,缓存一个空值或一个特殊值的数据
- 注意:如果缓存了空值或特殊值,要设置一个短暂的过期时间
缓存雪崩
- 缓存雪崩是缓存中大量key失效后,当高并发到来时导致大量请求到数据库,瞬间耗尽数据库资源,导致数据库无法使用
- 造成缓存雪崩问题的原因是大量key拥有了相同的过期时间
- 例如:对课程信息设置缓存过期时间为10分钟,当大量请求同时查询大量课程信息时,由于大量课程拥有相同的过期时间,所以大量课程的缓存信息也会同时失效,出现缓存雪崩问题
解决缓存雪崩
方法一:使用同步锁控制数据库的线程(性能不高)
使用同步锁控制查询数据库的线程,只允许有一个线程去查询数据库,查询得到数据后存入缓存
<img src=(https://myl-mdimg.oss-cn-beijing.aliyuncs.com/TyporaImg/学成在线.assets/image-20240125111225625.png“ alt=”image-20240125111225625” style=”zoom:67%;” />
方式二:对同一类型信息的key设置不同的过期时间
- 通常对一类信息的key设置的过期时间是相同的,这里可以在原有的固定时间基础上,加上一个随机时间,从而使他们的过期时间不相同
方式三:缓存预热
- 不用等到请求到来再去查询数据库存入缓存,可以写一个定时任务,提前将数据存入缓存。使用缓存预热机制,通常有专门的后台程序去将数据库的数据同步到缓存中
缓存击穿
- 缓存击穿是指大量并发访问同一个热点数据,当单例数据失效后,同时去请求数据库,瞬间耗尽数据库资源,导致数据库无法使用
- 例如:某手机新品发布,此时手机数据存在缓存中,如果在秒杀的时候,缓存刚好失效,那么此时就会有大量请求直接访问数据库
- 缓存击穿是指大量并发访问同一个热点数据,当单例数据失效后,同时去请求数据库,瞬间耗尽数据库资源,导致数据库无法使用
如何解决
方式一:使用同步锁控制查询数据库的线程,只允许有一个线程去查询数据库,查询得到的数据存入缓存
方式二:热点数据不过期
- 可以由后台程序提前将热点数据加入缓存,缓存时间设置不过期,由后台程序做好缓存同步
总结:
- 缓存穿透
- 去访问一个数据库不存在的数据,无法将数据进行缓存,导致直接查询数据库,当并发较大时,就会对数据库产生压力。
- 缓存穿透可以造成数据库压力增大,连接数等资源用完,最终数据库拒绝连接不可用
- 解决方案
- 缓存一个null值
- 布隆过滤器
- 缓存雪崩
- 缓存中大量key失效后,当高并发到来时,导致大量请求到数据库,瞬间耗尽数据库资源,导致数据库无法使用
- 造成缓存雪崩问题的原因是大量key拥有了相同的过期时间
- 解决方案:
- 使用同步锁控制
- 设置不同的过期时间,例如:使用固定数+随机数作为过期时间
- 缓存击穿
- 大量并发访问同一个热点数据,当热点数据失效后,同时去请求数据库,瞬间耗尽数据库资源,导致数据库无法使用
- 解决方案
- 使用同步锁控制
- 设置key永不过期
- 缓存穿透
9.2 分布式锁
- 本地锁的问题
- 上面的程序中使用了同步锁来解决缓存击穿、缓存雪崩的问题,保证同一个key过期后,只会查询一次数据库,但如果将同步锁的程序,分布式部署在多个jvm上,则无法保证同一个key只会查询一次数据库
什么是分布式锁?
本地锁只能控制所在JVM中的线程同步执行,现在要实现分布式环境下所有虚拟机中的线程去同步执行,就需要让多个JVM使用同一把锁,JVM可以分布式部署,锁也可以分布式部署
- 该锁不属于某个虚拟机,而是分布式部署,由多个虚拟机共享,这种锁叫分布式锁
分布式锁的实现方案
- 基于数据库实现分布式锁
- 利用数据库主键唯一的特性,或利用数据库唯一索引的特点,多个线程同时去插入相同的记录,谁插入成功谁就抢到锁
- 基于Redis实现分布式锁
- Redis提供了分布式锁的实现方案,例如:SETNX、Redisson等
- 拿SETNX举例,SETNX是set一个不存在的key(set if not exists),多个线程去设置同一个key,只会有一个线程设置成功,设置成功的线程拿到锁
- 使用zookeeper实现
- zookeeper是一个分布式协调事务,主要解决分布式程序之间的同步问题
- zookeeper的结构类似文件目录,多线程向zookeeper创建一个子目录(节点)只会有一个创建成功,可以利用此特点实现分布式锁,谁创建该节点成功,谁就获得锁
- 基于数据库实现分布式锁
SETNX实现分布式锁
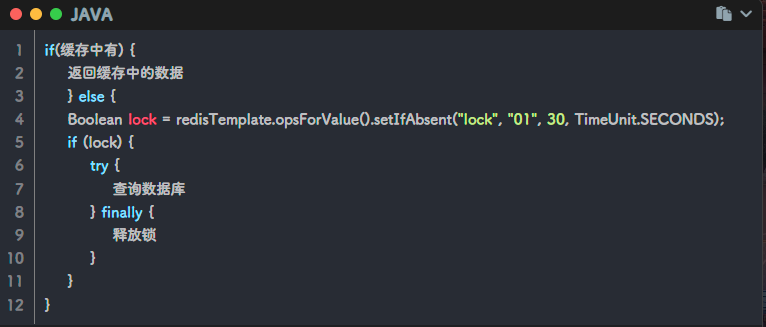
如何释放锁
key到期自动释放
- 因为锁设置了过期时间,key到期会自动释放,但是会存在一个问题:查询数据库时,还没操作完,key就到期了
- 由于key到期了,就会导致其他线程也拿到了锁,最终重复查询数据库,执行了重复的业务操作
- 怎么解决这个问题?可以将key的到期时间设置的长一些,足以完成查询数据库并设置缓存等相关操作。但是这个效率会低一些,而且到期时间也不好把握
手动删除锁
如果是采用手动删除锁,可能和key到期自动删除有冲突,造成删除了别人的锁
例如:查询数据库等业务还没执行完,此时key过期了,别的线程又拿到锁进来了,当上一个线程执行完查询数据库业务之后,手动删除锁,把新进来的线程的锁给删了
要解决这个问题,可以在删除锁之前,判断这个锁是不是自己的,伪代码如下
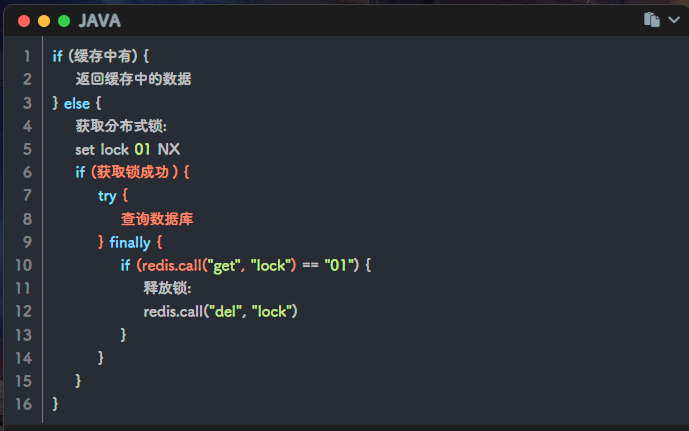
- 上述代码10~13行非原子性,也会导致删除其他线程的锁
- 想实现原子性,需要让redis去执行Lua脚本的方式去实现,这样就具有原子性,但是过期时间的值设置还存在不精准的问题
Redisson实现分布式锁(碾压setnx)
Redisson相比SETNX实现分布式锁要简单的多,其工作原理如下
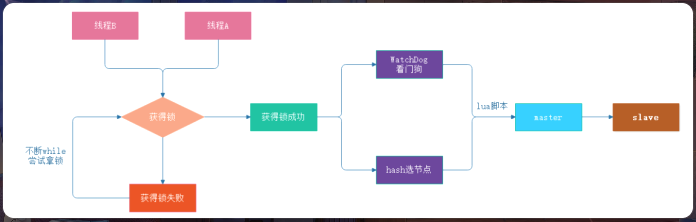
加锁机制
- 线程去获取锁,获取成功:执行lua脚本,保存数据到redis
- 线程去获取锁,获取失败:一致通过while循环常事获取锁,获取成功后,执行lua脚本,保存数据到redis
- WatchDog自动延期
- 第一种情况:在一个分布式环境下,假如一个线程获得锁后,突然服务器宕机了,那么这个时候在一定时间后这个锁会自动释放,你也可以设置锁的有效时间(当不设置默认30秒时),这样的目的主要是防止死锁的发生
- 第二种情况:线程A业务还没有执行完,时间就过了,线程A 还想持有锁的话,就会启动一个watch dog后台线程,不断的延长锁key的生存时间。
- Lua脚本保证原子性操作
- 主要是如果你的业务逻辑复杂的话,通过封装在lua脚本中发送给redis,而且redis是单线程的,这样就保证这段复杂业务逻辑执行的原子性
- 具体使用RLock操作分布式锁,RLock继承了JDK的Lock接口,所以他有Lock接口的所有特性,例如:lock、unlock、tryLock等特性,同时它还有很多新特性:强制锁释放、带有效期的锁
10 项目总结
10.1 项目开发技术点
1 接口开发

2 异常处理

3 前后端联调

4 解决接口跨域问题
解决

nginx代理
5 微服务之间的接口调用


- 解决
- 熔断
- 降级
- 限流
10.2 模块
1 内容管理
- 流程控制
- 课程审核
- 课程发布分布式事务方案
- 课程发布任务调度方案
- 页面静态化方案
- 课程搜索方案
2 媒资管理
- 断点续传
- 任务调度视频处理流程
- 文件服务访问方案
3 认证授权
- 认证流程
- 网关统一鉴权
- OAuth2
- 微信扫码流程
- 授权相关数据模型
- 验证码校验流程
- JWT令牌
- spring security工作原理
UserDetails和DaoAuthentication
4 选课学习
- 选课流程
- 在线学习流程
- 免费课程续期流程
5 订单支付
- 支付流程
- 生成二维码执行流程
- 用户扫码支付流程
- 支付结果通知流程
- 支付结果通知分布式事务


